Addressing Uneven Partition Lag in Kafka

Many companies choose Apache Kafka for their asynchronous data pipelines because it is robust to traffic bursts, and surges are easily managed by scaling consumers. However, scaling is not helpful when lag is concentrated on a small number of partitions. In this blog, we share our solution for this issue, hoping that it helps you address this issue in your own organization.
The Issue: Scaling Doesn’t Help With Uneven Partition Lag
One of the strengths of Kafka is that it makes the data pipeline resilient to traffic bursts by allowing lag to accumulate temporarily without losing events. When lag is uniform across all partitions on a given topic, it is typically addressed by adding new instances to the consumer group (aka horizontal scaling). This allows each new consumer to contribute evenly to processing the backlog.
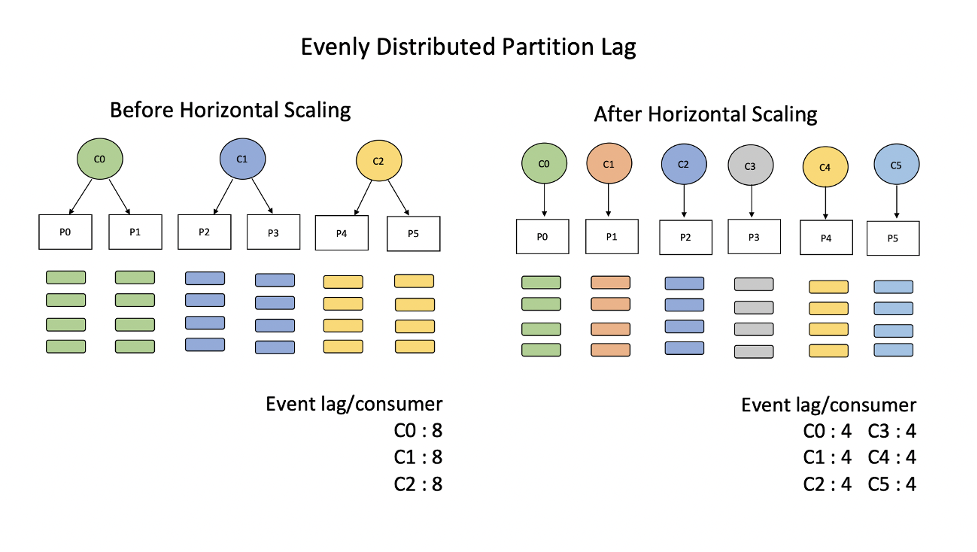
When lag is distributed evenly among partitions, each consumer has an equal backlog. Thus, adding new consumers in this case reduces the backlog on existing consumers proportionally.
However, when the lag is accumulated in one or a small number of partitions, then the backlog also falls on one or a small number of unlucky consumers. In this case, horizontal scaling is ineffective because it redistributes unlagged partitions, while the backlog remains concentrated on a few consumers, or even just one consumer.
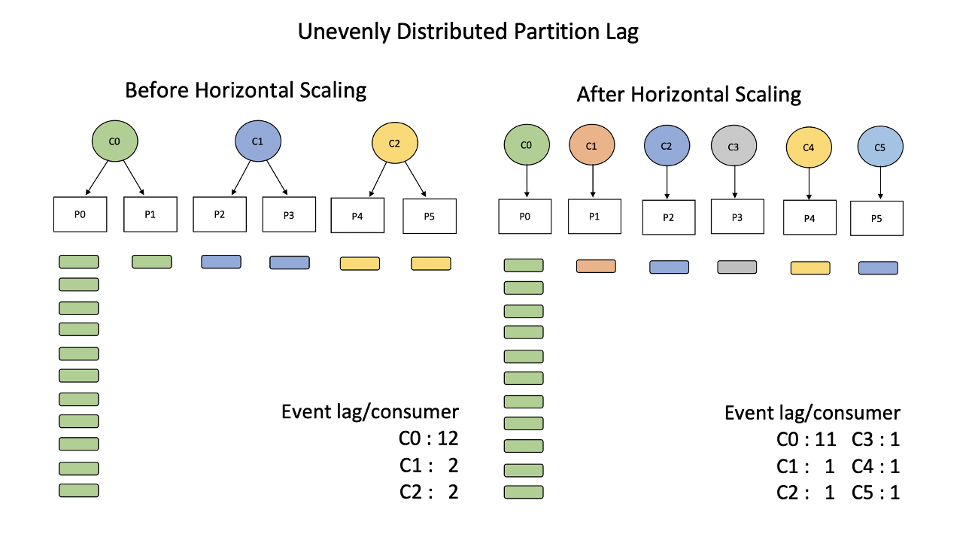
When lag is not evenly distributed, the impact of horizontal scaling is reduced. In the most extreme case, in which all of the lag resides on a single partition, the impact of horizontal scaling is negligible.
Unfortunately, there is no out-of-the box way to address the issue of these lag hotspots within Kafka. Two CrowdStrike interns, Niveditha Rao and Thy Ton, led our team in identifying a way to solve the issue of partition lags without using horizontal scaling. In this post, we explore our solution and how we coordinate it across our complex ecosystem of more than 200 microservices.
Fixing the Partition Lag in Kafka
In the simplest terms, our solution is to redistribute messages temporarily from a lagging partition to other non-lagged partitions.
We do this by adding an extra feature in our Kafka consumer library: a special mode that can be switched on or off so that messages will get redistributed to a different partition with the same topic. This is managed by a callback that alerts the service that messages in the lagging partition should be redistributed to other partitions, either on the same topic or a different topic. This eliminates any processing time on the Kafka worker, which in turn reduces the time required to clear the lagged partition. Messages are passed to other partitions, where they can be quickly picked up and processed normally.
In very simple pseudocode, the message handling looks like this:
//kafka message handler
foreach msg:
err = nil
if redistributor.isRedistributable(msg): //check msg topic and partition against current map
err = reproduce(msg) //bypass processing and produce to a different partition
else:
err = messageHandler(msg) //standard, and presumably slower, processing
handleErrorsAndCommit(msg, err) //commit to kafka
In the code above, our team added an additional check against the message metadata (topic and partition) to bypass standard processing for messages on lagged partitions. Assuming that the typical processing time is greater than the time required to produce the message back to Kafka, this will allow the impacted partition to be cleared very quickly. The processing latency can then be picked up by other consumers that are operating on non-lagged partitions.
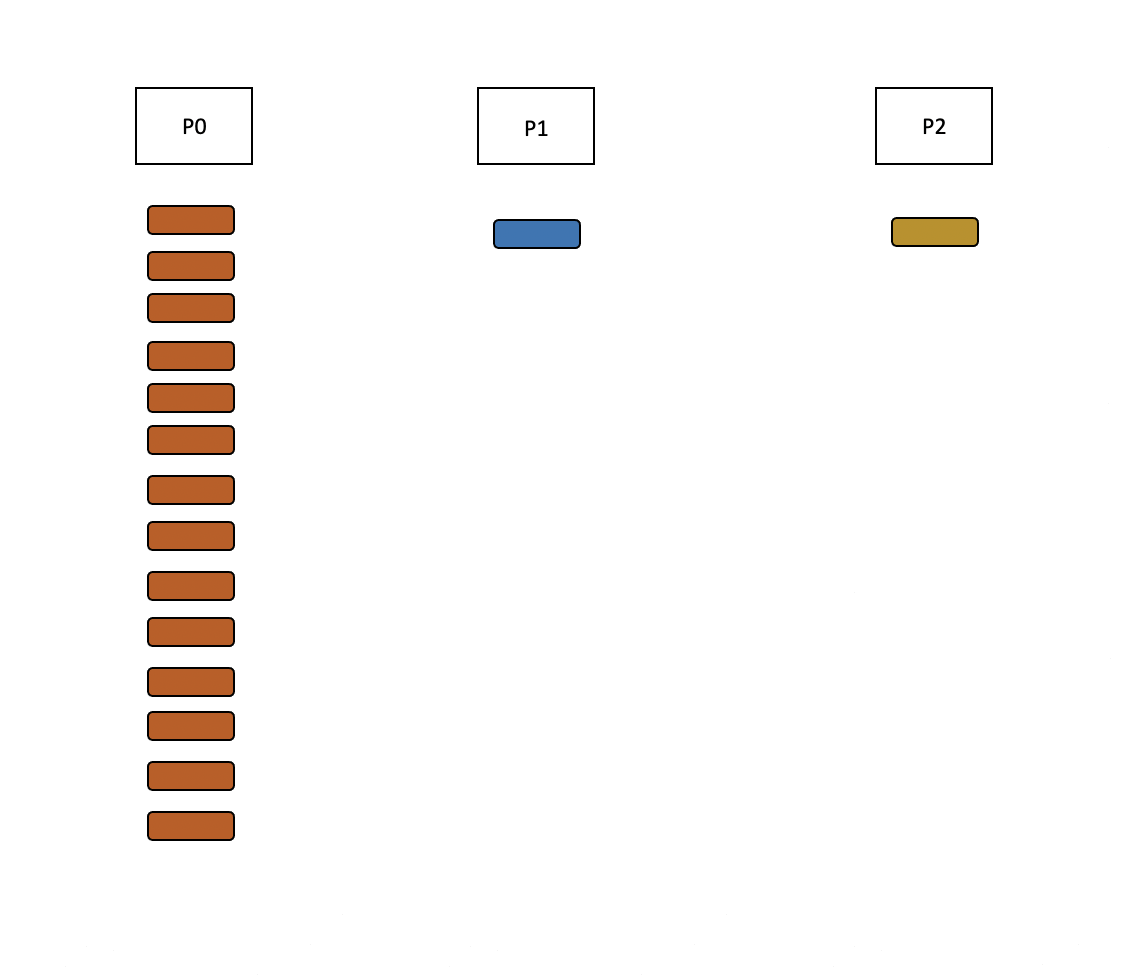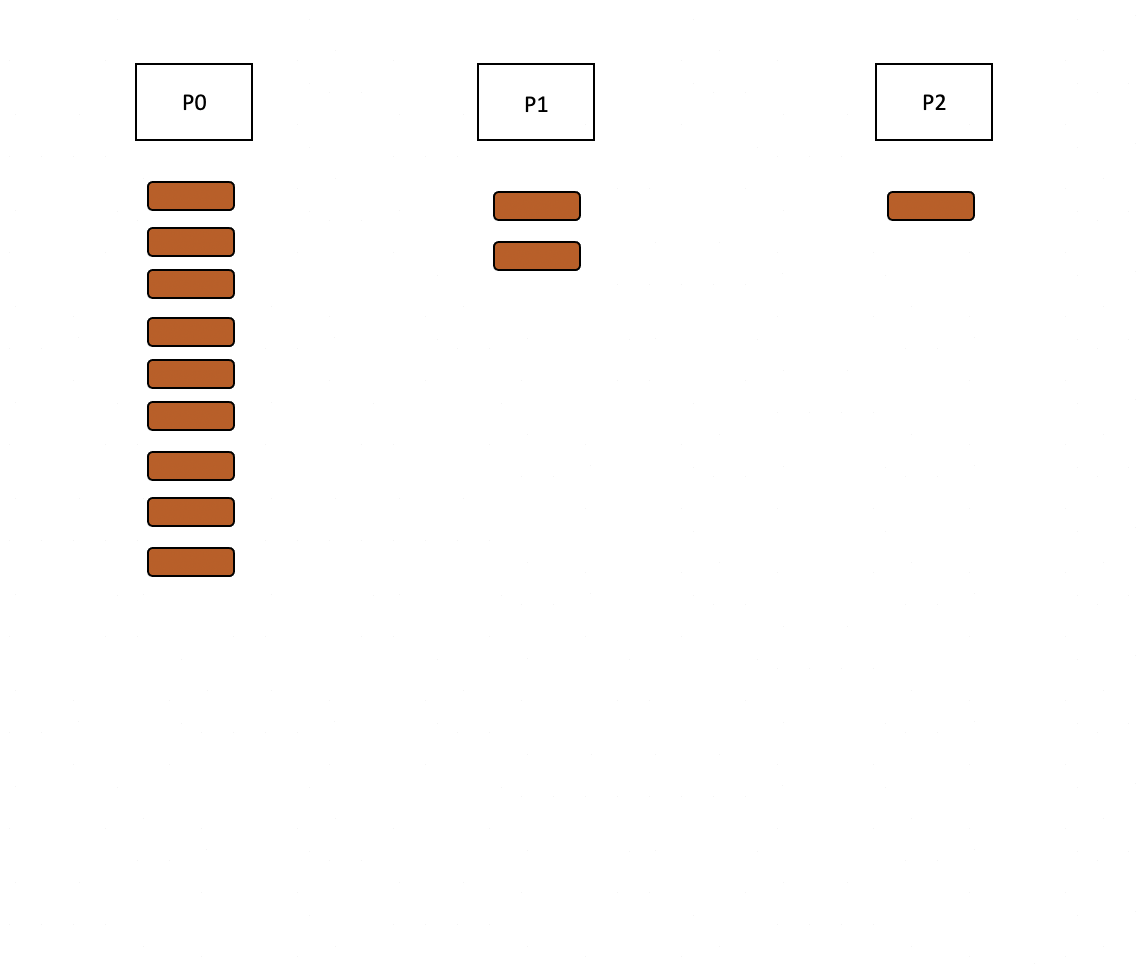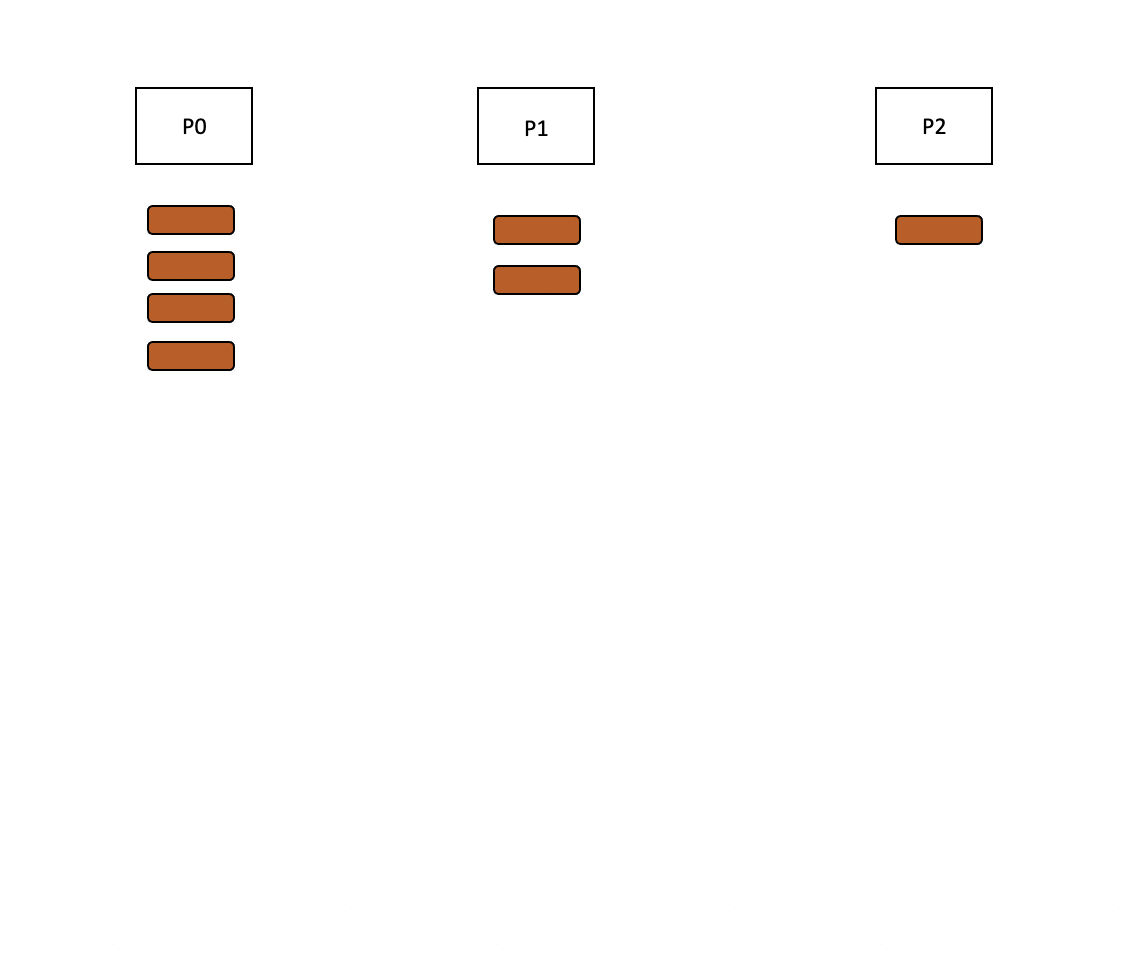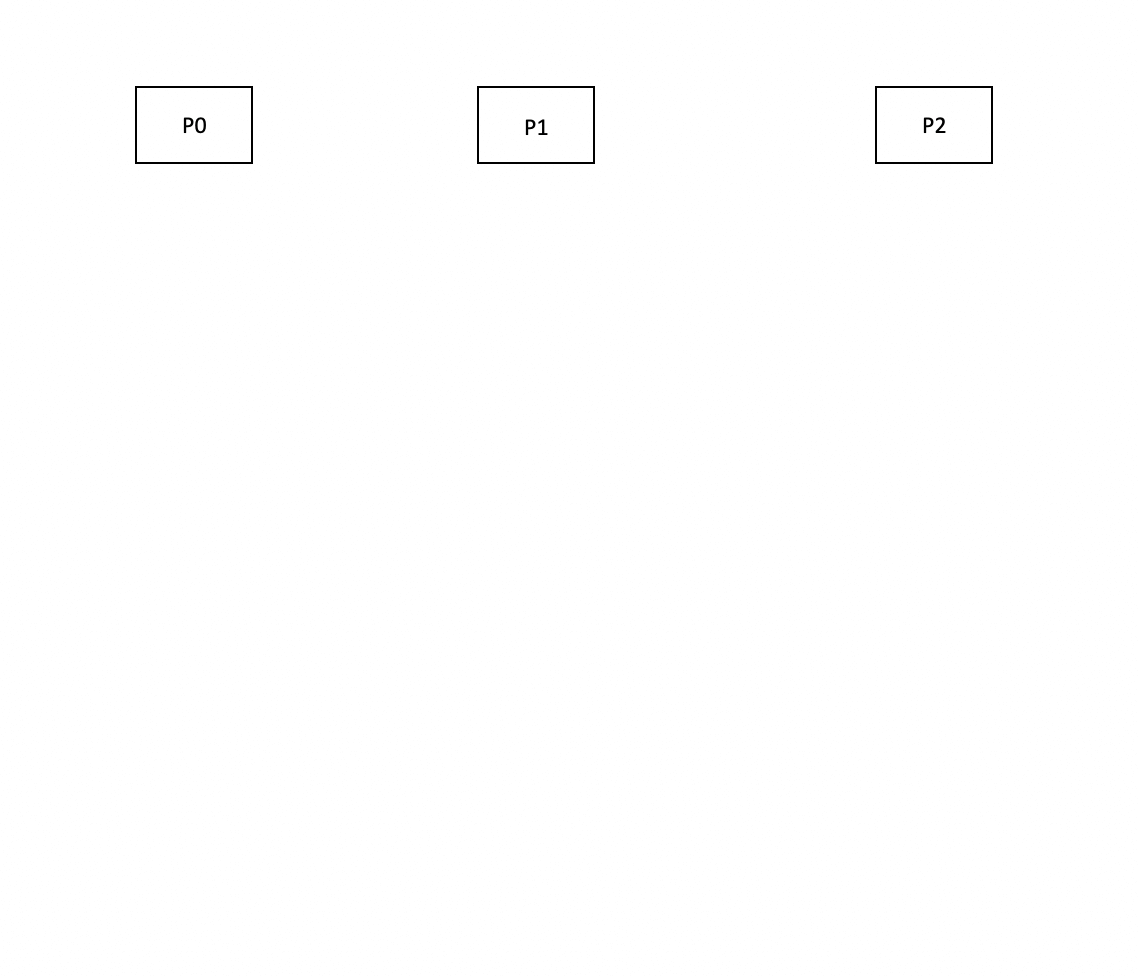
When redistribution mode is enabled, the consumer of P0 reads events, but skips processing and immediately reproduces events to any of the other partitions. The total processing time is therefore split over the remaining partitions.
Redistributing the messages in this way is a relatively straightforward solution that doesn’t require any horizontal scale-up — and hence, no added cost.
Coordinating Redistribution State via Redis
Because a Kafka consumer group can comprise multiple instances with no knowledge of one another, it is important to find a way to enable the redistributor state for a single partition via any instance such that all instances of the consumer group will be aware of the partitions that should be redistributed. In other words, if and when messages are being redistributed in Kafka, the system must maintain a single source of truth across all instances.
To enable redistribution mode, we implemented an API on the consumer instances to control the redistribution mode. The API is quite simple, consisting of a POST that accepts a map of topics to partition values and a GET that returns the current set of redistribution-enabled partitions. We use Redis as a distributed cache to share knowledge of the current redistribution configuration between all consumer instances. Consumer instances poll Redis periodically to retrieve the most current redistribution status.
The process looks like this:
- Enable redistribution for topics 1, 3 and 5 on some_topic
curl -X POST <consumer_endpoint>/redistribute -d ‘{“some_topic”: [1,3,5]}’ - The consumer instance that receives the POST updates the redistribution map in Redis
- All consumer instances retrieve the current map upon their next query to Redis
- Consumers begin redistributing messages received on partitions 1, 3 and 5, while messages on the remaining partitions are processed as normal
To disable redistribution, we submit a POST to the same /redistribute endpoint with an empty map, indicating that there is nothing to be redistributed.
Note that the redistribution map is keyed per consumer in Redis, so separate services can independently modify their own redistribution maps. In practice, however, redistribution is rare, so it’s unlikely that two services would simultaneously be in redistribution mode.
Special Considerations
- This solution is best suited to Kafka topics with a single consumer group. If the topic has multiple consumer groups and only one consumer group is lagging, then the other consumer groups will end up double-processing messages.
- This solution does not consider how or why the lag is uneven. The most common causes are unhealthy Kafka brokers or unhealthy consumers. In any case, message redistribution is a good option if the underlying issues have been resolved.
- It is important to disable your redistributor when the lag is clear. If not, you will handicap your service. Future work will automate disabling redistribution based on lag metrics.
- This approach assumes that the Kafka worker processing time is large compared to the time required to consume and reproduce a message. Otherwise, redistribution is just added latency.
If you have your own ideas and questions on this topic, we invite you to drop us a message on social media @CrowdStrike.

