In part one of this series on Kafka logging, we reviewed Kafka’s architecture and how it manages logs using named partitions inside topics. We also looked at some common commands to create and manipulate the topics using the console APIs.
In addition, we touched on how the append-only nature of Kafka logs can quickly result in high disk consumption. This can cause various issues, including slower data access or the inability to store larger messages. To address this, Kafka provides log retention policies, allowing you to store data in queues as purposefully as possible. You can also employ different compaction techniques with Kafka.
In part two, we’ll discuss these advanced compaction techniques and how to implement them within your Kafka cluster. We’ll also learn how to perform basic read and write operations to observe the compaction behavior.
Learn More
Explore the complete Kafka Logging Guide series:
- Part 1: The Basics
- Part 2: Advanced Concepts
- Part 3: Managing Performance Logs
- Part 4: Securing Kafka Logs
What Is Kafka Log Compaction?
Compaction ensures that the latest and most relevant data exists. It eliminates data that is either redundant or no longer useful, thereby reducing disk utilization. Compaction simplifies traversing and backing up data while maintaining data integrity and consistency across your servers.
You can achieve compaction through different techniques, including:
- Compressing and then deleting the data
- Removing older records after they’ve passed a specified time threshold
Log compaction is a mechanism that allows robust control at the record level as well as at the system level. By using log compaction, you can decide which events to store in logs and for how long. You can also choose what data is not compacted at all.
Retention Based on Time or Size
A common approach to compaction is to use time- or size-based retention policies, either at the server level or the topic level.
Time-Based Retention Policy
Time-based compaction in Kafka is one of the basic techniques designed for a simpler and easier cleaning process of all cluster sizes. You can enable time-based retention by configuring the following properties:
log.retention.hourslog.retention.minuteslog.retention.ms
The default value for retention is 168 hours (seven days). For the above three properties, precedence is given to the smallest unit, meaning log.retention.ms takes the highest precedence. Setting a retention policy to a larger value will cause events to pile up inside the brokers. A smaller value might lead to data loss, as few consumers are running during the compaction period. Therefore, the correct value has to be determined according to the application and the user’s need to keep data relevant and available.
Consider the example below, in which we use the log.retention.ms property to set a retention policy of 600 milliseconds.
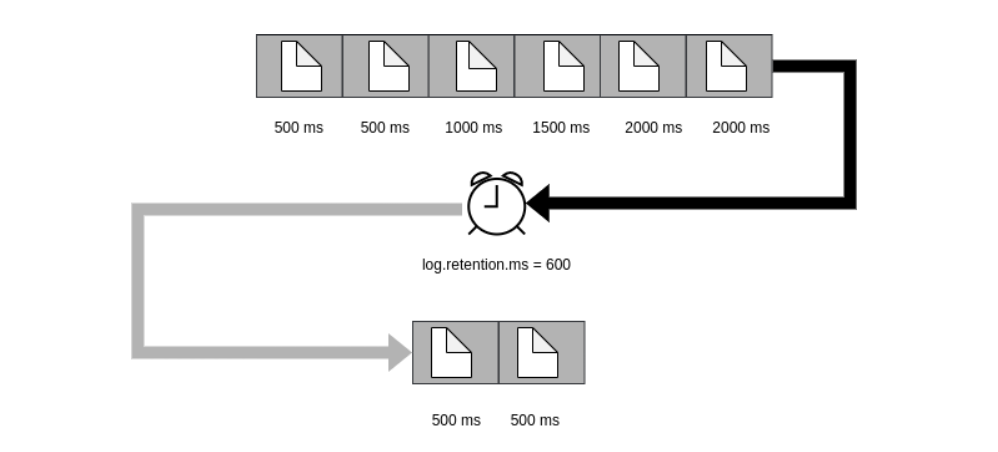
Messages in Kafka will have a time to live (TTL) of 600 milliseconds, after which they are marked for deletion.
Size-Based Retention Policy
As an alternative, you can use size-based retention, compacting logs by configuring a size limit. For this, you would set the log.retention.bytes property to a value that best suits your application. By default, the threshold is set to -1, effectively disabling size limiting on the partitioned topic.
In the example below, the configured size threshold is 800 MB. The total size of the partitioned topic is kept at less than 800 MB.
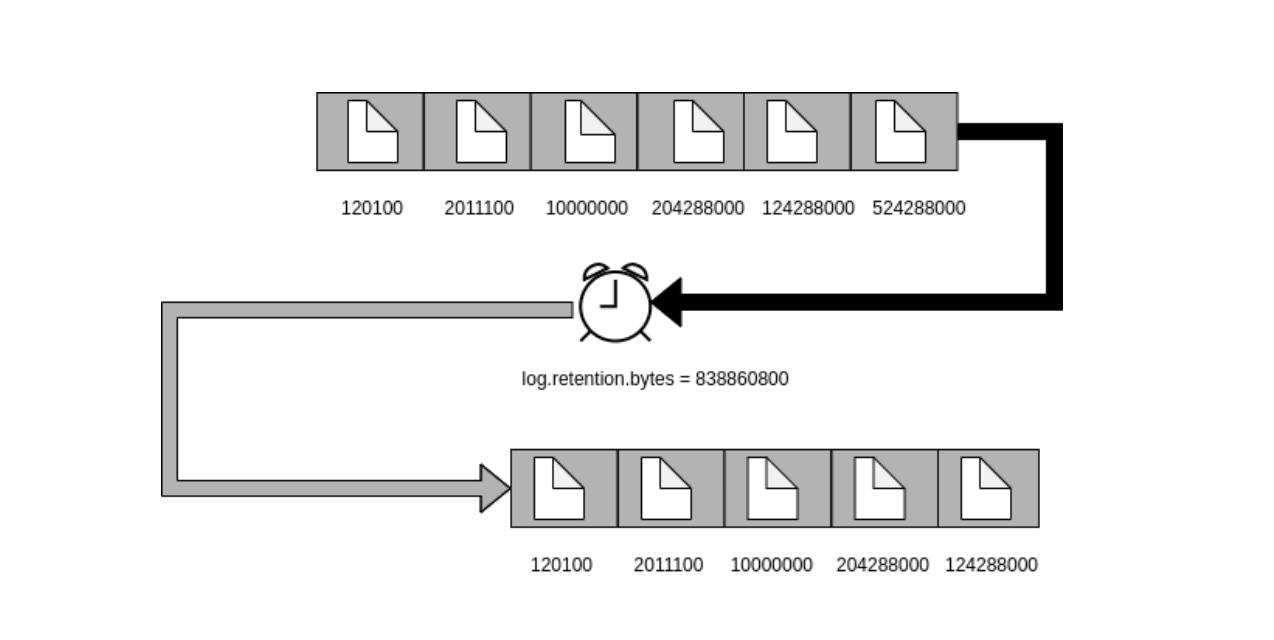
Time with Size-Based Retention Policy
Both retention policies are powerful on their own, but you can combine these two policies in the Kafka nodes to further fine-tune the compaction process. The compaction process triggers separately for each configuration, maintaining highly compacted topics in the Kafka cluster.
Limitations of Server Level Retention Policies
As you can see, applying compaction policies on the server alleviates disk congestion issues and provides comprehensive control over the data. However, only applying retention policies at the server level won’t handle streams of data efficiently. For this, Kafka provides an enhanced compaction mechanism, targeting a single record in each topic by managing keys and offsets intelligently.
Kafka Log Compaction
Another technique for conserving disk space — specifically referred to as log compaction in Kafka — is a mechanism to maintain the last known value of each key inside every partition. Kafka’s documentation describes the technique this way:
Log compaction is a mechanism to give finer-grained per-record retention rather than the coarser-grained time-based retention. The idea is to selectively remove records where we have a more recent update with the same primary key. This way, the log is guaranteed to have at least the last state for each key.
The mechanics behind Kafka’s log compaction algorithm and process are beyond the scope of this article, but a detailed description can be found here.
How To Manipulate a Compacted Topic
Creating a Compacted Topic
To create a compacted topic, you need to call the console topic API and set the cleanup.policy property to compact, along with a reasonable number for retention. You can find the console APIs inside the Kafka bin directory on the Kafka server.
:~$ sh kafka-topics.sh --create --topic ls-compact-topic --partitions 3 --replication-factor 2 --bootstrap-server localhost:9065 --config “cleanup.policy=compact” --config “delete.retention.ms=150”
For the above command, once the ls-compact-topic topic reaches a threshold to indicate it needs to be compacted (this is called the “dirty ratio” and defaults to 50%), all the records older than 150 milliseconds are marked for compaction.
Publishing to the Compacted Topic
The following command publishes comma-separated key values to the ls-compact-topic using the console producer API.
:~$ sh kafka-console-producer.sh --topic ls-topic --bootstrap-server localhost:9065 --property parse.key=true --property key.separator=,:~$ key1,ls1
:~$ key2,ls2
:~$ key1,ls4
:~$ key4,ls6
:~$ key3,ls3
:~$ key3,ls5
Consume the Compacted Topic
The following command consumes the ls-compact-topic and prints the key-value pairs, using the console consumer API.
:~$ sh kafka-console-consumer.sh --topic ls-topic --bootstrap-server localhost:9065 --property print.key=true --property key.separator=, --from-beginning
Assuming the compaction process has been completed on all segments, the above command would yield the below result:
key1,ls4key2,ls2
key4,ls6
key3,ls5
Creating Retention Policies on a Topic
In this section, we’ll expand further regarding the impact of compacted policies on the logs.
Applying Server-Level Retention Policies in a Kafka Cluster
To update the retention configuration on the Kafka server, navigate to the config folder inside the Kafka directory and edit server.property file. Set the following configuration:
log.retention.bytes=800000000
This retains messages in all topics such that topics can reach a size of 800 MB.
Creating and Inspecting a Compacted Topic
Let’s assume we have created a compacted topic called ls-super-topic using the topic console API command, and we have set the log retention policies for this topic to 120 milliseconds and 800 MB.
Now, we can use the --describe flag command to view the retention property.
:~$ sh kafka-topics.sh --describe --topic ls-super-topic --bootstrap-server localhost:9065
Notice the topic has both time and size retention policies assigned to it.
retention.ms=120retention.bytes=800000000
Creating a Compacted Topic with a Size-Based Retention Policy
Next, let’s create a compacted topic called ls-size-topic without specifying any retention property in the command. By doing so, we allow the topic to inherit the server’s retention policy.
:~$ sh kafka-topics.sh --create --topic ls-size-topic --partitions 3 --replication-factor 2 --bootstrap-server localhost:9065 --config “cleanup.policy=compact”
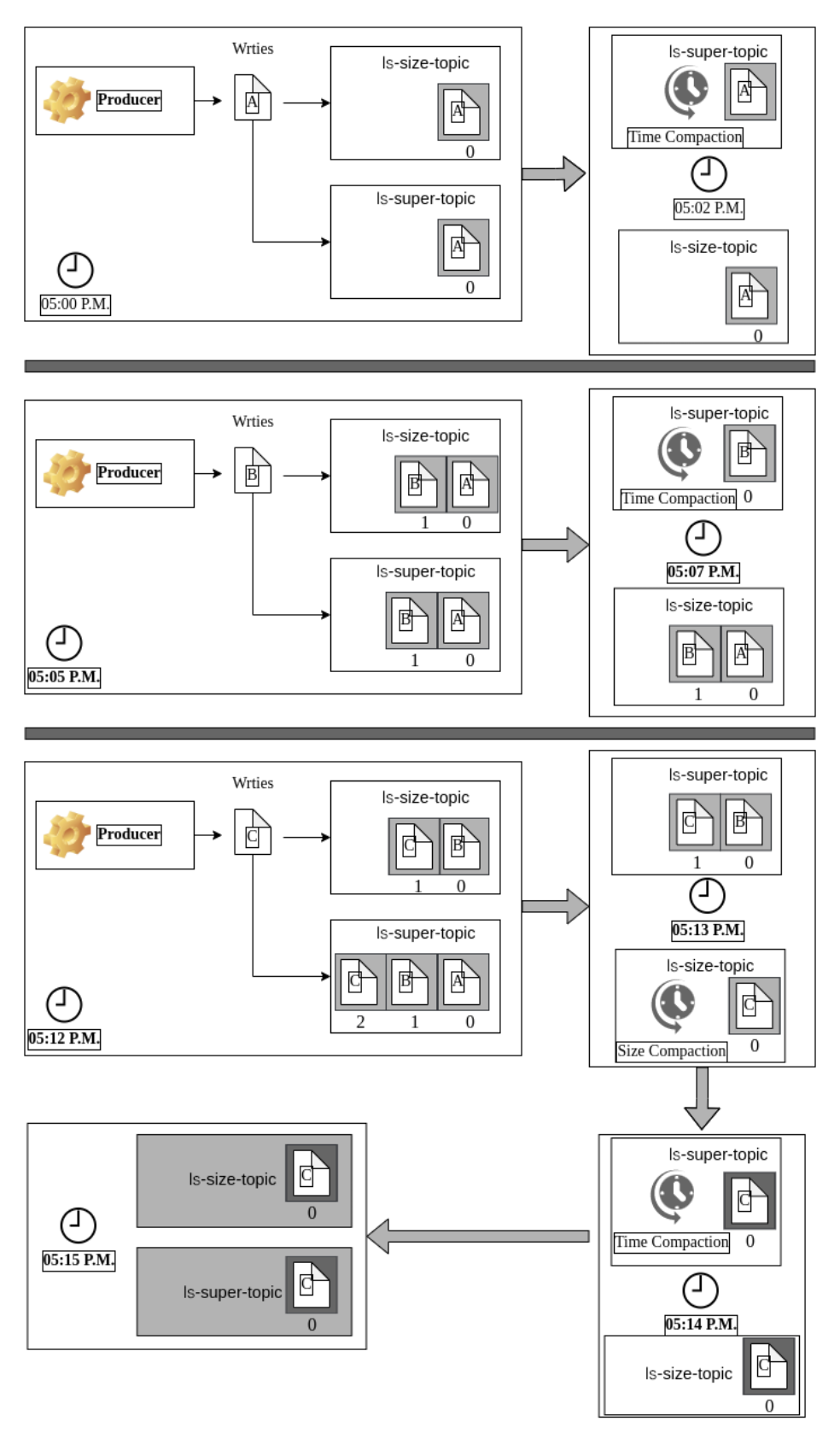
Observing the Behavior of These Two Topics
Suppose you have published three records using the same key, simultaneously to both the topics, as shown in the illustration below. You might notice how drastically the outcome changes based on the different policies. The compaction process is triggered every 120 milliseconds on the ls-super-topic, but the cleaner process is called on ls-size-topic only when the total size exceeds 800 MB.
Log your data with CrowdStrike Falcon Next-Gen SIEM
Elevate your cybersecurity with the CrowdStrike Falcon® platform, the premier AI-native platform for SIEM and log management. Experience security logging at a petabyte scale, choosing between cloud-native or self-hosted deployment options. Log your data with a powerful, index-free architecture, without bottlenecks, allowing threat hunting with over 1 PB of data ingestion per day. Ensure real-time search capabilities to outpace adversaries, achieving sub-second latency for complex queries. Benefit from 360-degree visibility, consolidating data to break down silos and enabling security, IT, and DevOps teams to hunt threats, monitor performance, and ensure compliance seamlessly across 3 billion events in less than 1 second.
Arfan Sharif is a product marketing lead for the Observability portfolio at CrowdStrike. He has over 15 years experience driving Log Management, ITOps, Observability, Security and CX solutions for companies such as Splunk, Genesys and Quest Software. Arfan graduated in Computer Science at Bucks and Chilterns University and has a career spanning across Product Marketing and Sales Engineering.