





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



















































CrowdStrike’s mission is to stop breaches. We continuously research and develop technologies to outpace new and sophisticated threats and stop adversaries from pursuing attacks. We also recognize that security is best when it’s a team sport. In today’s threat landscape, technology collaboration is essential to deploy novel methods of analysis and defense.
When the team behind Intel® Threat Detection Technology (Intel® TDT) contacted us about the Neural Processing Unit (NPU) in the new Intel® Core™ Ultra processors, we were excited to collaborate with them on new possibilities for enabling AI-based security applications on endpoint PCs. This, combined with the supply chain security and built-in features of Dell commercial PCs, brings deep BIOS-level visibility and defenses to this innovative collaboration. If you missed Part 1 of our endpoint research collaboration on the new NPU, be sure to check it out here.
In this blog, we explain cluster and similarity assessment, its value to cybersecurity teams, and how CrowdStrike and Intel worked together on exploring this approach to endpoint security.
Value of Clustering and Similarity Assessment on Endpoint
Feature vectors (FVs) are lists of observed phenomena (or features) that are used as inputs to machine learning. Features can come from static file data, in-memory process scanning, local behavioral monitoring, cloud logs and other resources. For security applications, these are chosen to differentiate between malicious and benign software. Clustering and similarity assessment determines when an input feature vector relates closely to other FVs and when these form clusters of closely related FVs.
This assessment method enables the recognition of when data indicates an entity or set of operations is related to other examples and how they are similar. This is a valuable method for spotting malware trends. For example, malware families share similar features. New trends in malware development will morph these shared features, producing new sets of similar malware. Clustering and similarity assessment can help identify these new sets. It can also determine when new malware samples are the same as earlier malware versions but altered in an attempt at obfuscation (such as with polymorphism, or introduction of trivial behaviors) to thwart recognition by signature-based security software.
Counter-Polymorphism and Recognition of New Malware Variants
Malware authors often attempt to evade detection by introducing minor variations in static file-based data, adding noise with behaviors of no consequence such as repetitive and unnecessary Windows Registry activity, altering the order of behaviors and other tactics. Strict matching of these files misses that they are the same malware. However, with clustering and similarity analysis, it is possible to detect efforts to hide malware and the true nature of the malware identified.
One advantage of determining this similarity is that a new variation of malware modified through polymorphism can be confidently assessed as an example of a previously observed malware family. The results of earlier analysis on that initial family can be inferred to apply to the new malware instance — meaning it can be blocked before it causes any damage. For example, an earlier instance of malware might have been extensively analyzed by human researchers. This analysis can be inferred to apply to a new variation of the malware if the similarity assessment shows it is warranted.
Dynamic Clouding and Identification of Multi-system Campaigns
Clustering and similarity can also provide an advancement in the methodology for determining when more data should be sent to the cloud for in-depth analysis. Normally, this decision is made with heuristic (rule) evaluations and statistical methods. A clustering and similarity assessment supports a more dynamic decision and allows for targeted gathering of valuable data. For example, if there are gaps in observed instances of a trending malware family, a dynamic decision driven by clustering and similarity could help gather endpoint data to fill in those gaps.
Decisions on when to apply more endpoint analysis can also be made on the basis of clustering and similarity. For example, an endpoint similarity assessment could be used to better govern when in-memory scanning of a process should be performed.
Additionally, a similarity assessment against a set of centroids from a larger FV set held in the cloud can provide a gauge of similarity to members of the clouded set. This allows an endpoint to determine similarity to members of the full set without the burden of holding the full set of FVs or transferring the full entirety of data to the endpoint.
This gauging of similarity to the full clouded set of data also allows recognition of how observed data fits within a larger campaign, such as a multi-system attack (of value to XDR). An individual endpoint will lack the data to recognize this, but correlating data from several endpoint systems will allow observation of the full attack campaign. Each endpoint has a piece of the puzzle: If they can recognize the need to send their data to the cloud, this assembled view becomes possible.
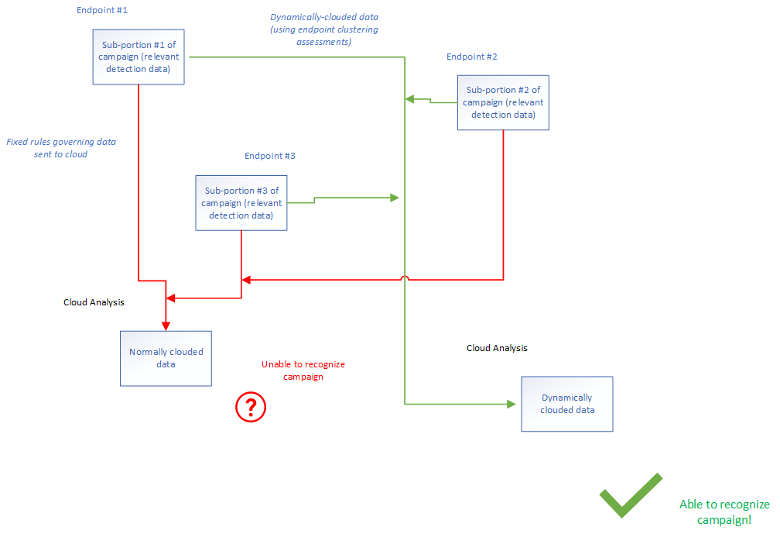
Figure 1. This illustrates how incorporating data observed on disparate endpoints forms a recognition in the cloud that a multisystem campaign is underway, and showcases how the cloud would not have sufficient data from the endpoint to recognize this without the support of clustering-driven dynamic clouding.
Dynamic Forensics Data Gathering
Clustering and similarity are also valuable in enabling dynamic expansion of forensic data collection. To preserve endpoint resources, journaling of data for possible forensic analysis must be limited in scope. For example, a continuous log of Windows events will use too much disk space if left running for long. Because of this limitation, a rolling window of collection will typically be used where the newest data overwrites the oldest, thus limiting the log size. However, doing so means that if participation in an attack is not detected until after the rollover has occurred, relevant data on an endpoint will be overwritten and lost.
Advanced and multi-system attacks often move slowly and lay the groundwork for a later launch of a full attack by setting persistence for components of the attack, establishing communications systems, establishing hiding places and taking other actions. The forensics needed to understand how these steps were accomplished will be lost if the attack was detected after the journaling rollover occurred. A system using clustering and similarity on the endpoint can recognize that local data indicates a value in extending the journaling of data by sending it to the cloud.
Further, the data may not have been collected in the first place without reason. Consider high-spinning operations such as writes to the Windows Registry. Normally, the volume of these events would prohibit recording in a journal for forensics. With a system using similarity and clustering operating on the endpoint, a decision can be made to perform targeted data collection of relevant Windows Registry writes. The clustering and similarity comparison could determine that local endpoint data indicates a component of a suspicious activity is likely operating on the endpoint. This would trigger collection of data likely to be relevant, such as the Windows Registry operations cited in the example.
The Challenges of Enabling Endpoint Clustering
The CrowdStrike Falcon® platform is engineered to operate in a transparent and near-zero impact manner, allowing seamless deployment to the endpoint.
This drive to near-zero endpoint impact is at odds with using clustering and similarity assessment, as these often require a substantial volume of feature vector comparisons. For example, comparing a set of 100 FVs against another set of 1,000 FVs requires 100,000 FV comparisons.
The pain points for deploying clustering and similarity assessment to the endpoint include a number of technical challenges that can impact system performance, including CPU usage spikes, endpoint memory usage and network bandwidth.
CPU Usage Spikes
In order to represent the richness of the collected information, many FVs can be quite long and may have more than 10,000 optional fields. As a result, comparing n-to-n sets of FVs may occupy the CPU unless the calculation is simplified and/or offloaded to an accelerator like iGPU (integrated GPU) — particularly if done repeatedly, such as in response to frequent events. This surge of demand on the CPU can have a significant impact on the endpoint’s system performance.
Moreover, the similarity between raw data FVs may or may not completely indicate whether they belong to the same group (such as a benign app versus a backdoor malware). This uncertainty is because large groupings such as “backdoor” encompass a wide range of features that can include overlap with other groups including benign software.
A more sophisticated “featurization” can help, with the NPU-offload enabling what would otherwise be a CPU-intensive task.
Endpoint Memory Usage
Loading large sets of known FVs on endpoints as comparison points consumes a significant amount of system memory. This can be partly mitigated by representing the large set using centroids — a single “average” data point in the middle of each major cluster. However, due to the significant length of some FVs, with enough different cluster centroids more memory than is desirable may still end up being used.
Network Bandwidth
Downloading large sets of FVs consumes network bandwidth, as does uploading large sets of FVs and journaled forensics data to the cloud. The impact on bandwidth can be partly mitigated by using centroids to represent each group or cluster within the data.
However, the CPU impact of repeatedly performing such comparison volume will be felt. In addition, holding endpoint operations while performing these comparisons would further impact the system.
Next, let’s explore how Intel’s data science team was able to use the NPU to help address these performance issues.
The Intel Neural Processing Unit (NPU)
The Intel Neural Processing Unit (NPU) is available in new Intel Core Ultra processors. The NPU is purpose-built to accelerate and offload inference operations, such as those used with deep learning and neural networks.
Using the NPU, we observed a drop in CPU usage from 35% to less than 1% for inference with a fully connected NN embedding — a neural network approach to clustering assessment.
When CrowdStrike explained the desire to do clustering on the endpoint and provided a sample dataset of FVs, the Intel TDT data science team set to work to make endpoint clustering practical against the challenges listed above.
The solution was to use a deep learning style embedding to intelligently re-encode the FVs in a much shorter form. This embedding was trained to learn which differences between FVs matter for building clusters.
Since this embedding model can be offloaded to the NPU, the following advantages are obtained:
- A significantly shorter FV means far fewer calculations when computing the distance between two FVs for clustering, reducing CPU usage. For batch operations, these calculations could be offloaded to the integrated GPU as well.
- There is no longer any need to run featurization on the CPU as it is handled entirely by embedding a network on the NPU. As a bonus, humans also no longer need to carefully craft featurization by hand, as it is created automatically.
- Since the centroids are now in the embedded space, they take up less memory.
- Because the embedded FVs are much shorter, sending them over the network now requires far fewer packets/bytes.
To test this idea, the Intel TDT team built a proof of concept (PoC) using the sample FV data provided by CrowdStrike. This PoC model was able to convert a sparse FV vector of nearly 5,000 fields into a dense vector of only 16! Moreover, the embedded FVs showed good results using K-means clustering classification, as can be seen in the following t-SNE clustering visualizations showing the ground truth labels vs. the generated classification clusters in the embedded space.
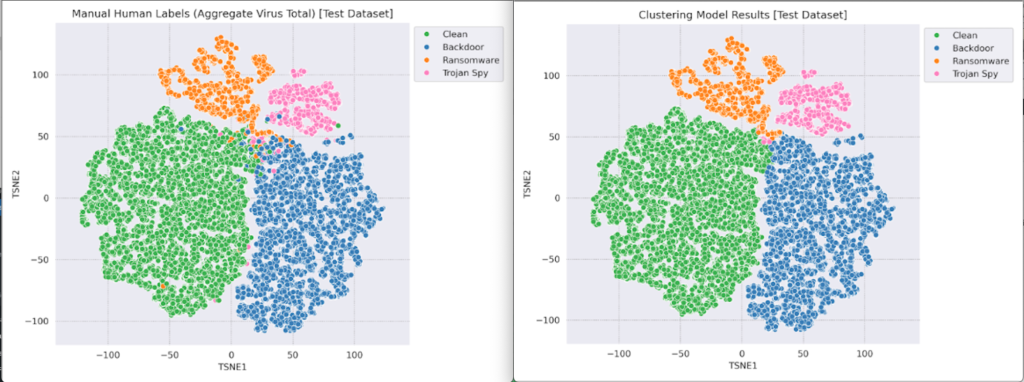
Figure 2. t-SNE clustering visualizations showing the ground truth labels vs. the generated classification clusters in the embedded space
The t-SNE charts in Figure 2 compare the clustering from the neural network-based clustering model (chart on the right) and the human-authored labels (used as a validation set).
Next, the performance characteristics of the PoC model were measured on the Intel NPU. When running the embedding model on the NPU, the CPU usage was less than ~1% systemwide overhead — within an acceptable performance envelope. For comparison purposes, running that same embedding neural network on the CPU instead leads to ~35% systemwide CPU usage on the test system. This demonstrates the performance overhead of embedding operations without making use of hardware acceleration.
Offloading from the CPU to the NPU enables applications of clustering on the endpoint that otherwise would be untenable.
| Device | Inferences per Second | Average Inference Time (msec) | CPU Util% | Memory Usage (MB) | First Inference Time (msec) |
| CPU | 202 | 4.94 | 35.0% | 57 | 6.23 |
| GPU | 233 | 4.28 | 14.0% | 108 | 6.81 |
| NPU | 386 | 2.59 | 0.5% | 85 | 34.13 |
The first inference time is higher with the NPU due to initialization costs. This is expected to drop with optimization.
Partners for the Road Ahead
The historical limitations of running AI workloads on an endpoint are undergoing a transformative shift with the integration of the NPU in Intel Core Ultra processors. Previously unattainable endpoint workloads become not only feasible but highly practical via NPU acceleration of deep learning neural network AI. The NPU shoulders the majority of the inference work, alleviating the processing burden on the CPU and resulting in minimal system impact, essentially making significant performance gains by running the right workloads on the right execution engines.
This breakthrough unlocks a realm of new possibilities, including moving endpoint detection closer to the source while sending relevant data to the cloud for in-depth analysis. Furthermore, the decision to dispatch additional data to the cloud can now be clustering and AI-driven, replacing fixed rules with dynamic clouding decisions. This empowers expanded, selective cloud data collection, ensuring scalability, minimizing network traffic and enhancing what CrowdStrike’s cloud analysis system can work with.
Leveraging the NPU on Intel Core Ultra processors to enable clustering and similarity assessment at the edge brings new levels of integrated and cloud-driven defenses to the endpoint. Numerous other use cases are conceivable, including endpoint analysis of network traffic, application to data leakage protection and more, building upon Intel’s existing security foundation in Intel vPro devices. We continue to explore the power of pushing more AI to the edge for advanced cybersecurity applications using the NPU, aiming to secure the future and stop breaches everywhere. Watch for future updates from this ongoing collaboration with Intel and Dell as CrowdStrike determines a productization roadmap to bring these features to our joint customers.
As we continue to develop next-gen capabilities, remember that CrowdStrike, Intel and Dell already offer supercharged threat detection. To shrink the IT and security gap, we combined forces to deliver an integrated endpoint defense framework. With eCrime breakout time dropping to an average of 62 minutes in 2023, organizations must accelerate detection and response to combat modern threats. This “hardware-assisted” security solution is unlike anything we’ve done before. It allows administrators to combine CrowdStrike’s cloud-based, AI-native defense with Dell and Intel’s device-level telemetry for visibility and observability at the firmware level — an area where we have seen an uptick in malicious and persistent threats in recent years. Disrupt the stealthiest attacks and get more value out of your technology investments with providers that know how to work together.
Additional Resources
- Watch Intel and CrowdStrike Enhance Cybersecurity with AI and NPU video.
- Learn more in this blog post: CrowdStrike and Intel Corporation: Addressing the Threat Landscape Today, Tomorrow and Beyond
- Get a full-featured free trial of CrowdStrike Falcon® Prevent and see how true next-gen AV performs against today’s most sophisticated threats.

