





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



















































- CrowdStrike combines the power of the cloud with cutting-edge technologies such as TensorFlow and Rust to make model training hundreds of times faster than traditional approaches
- CrowdStrike continuously advances cybersecurity machine learning capabilities to set the industry standard in protecting customers from sophisticated threats and adversaries
Supercharging CrowdStrike’s artificial intelligence requires both human professionals and the right technologies to deliver blisteringly fast and accurate machine learning model training with a small footprint on the CrowdStrike Falcon®® sensor. CrowdStrike data scientists continuously explore theoretical and applied machine learning research to advance and set the industry standard in protecting customers from sophisticated threats and adversaries. In recent years, deep learning models have achieved incredible performance in a variety of machine learning tasks, especially in the areas of computer vision and natural language processing. A major reason for deep learning’s mainstream adoption can be credited to the rise of powerful and open-source deep learning frameworks, the two most popular being PyTorch and TensorFlow. These frameworks provide extensive capabilities, documentation and tools to build machine learning models. Even with these excellent resources, implementing a fast end-to-end training workflow can be challenging. Various factors, including the type of computing resources used and how data processing is implemented, can contribute to how long it takes to train a model. Here we share some details and insights on the journey to a faster training pipeline for one of CrowdStrike’s latest text classification models.
Building an Initial TensorFlow Training Pipeline
TensorFlow is a powerful open-source machine learning library that provides a comprehensive and flexible ecosystem for building machine learning models in Python. It provides an intuitive high-level API (Keras) and thorough documentation with examples on how to get started building a model training pipeline.
A common first step to model development is to get a simple model training workflow running on a local machine with a small amount of data, before scaling up to training on the full dataset. The training workflow consists of reading in each file, processing the data (equivalent to feature extraction for our use case), training the model and evaluating model results. TensorFlow’s tf.data is used to create the data pipeline, as its API enables building input pipelines from simple and reusable pieces, optimized to read in data and do transformations efficiently as part of the model training process.
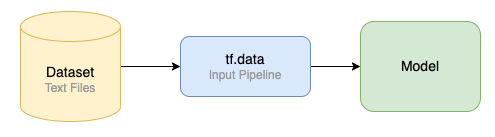 Figure 1. Simplified view of the initial training pipeline
Figure 1. Simplified view of the initial training pipelineInitial Training Results
With an end-to-end training pipeline working on a small data subset, it’s time to train on the full training dataset, consisting of 1.9 million text files and totaling over 70 GB of data.
Using a MacBook Pro with 32 GB CPU memory and 2.3 GHz 8-core Intel i9 processor, total training takes 65 epochs to complete (an epoch in machine learning means one complete pass of the training dataset). With each epoch taking roughly 3 hours and 30 minutes, this results in a total training time of approximately 227 hours — more than 9 days! Based on these training times, the need to speed up model training is clear, as many more model training runs are required for hyperparameter tuning and feature experimentation.
| Trained On | Training Dataset | Total Training Epochs | Total Training Time |
| MacBook Pro Laptop | 1.9 million text files | 65 | 227 hours |
Analyzing Our Training Pipeline with TensorBoard Profiler
In addition to the comprehensive Python API that TensorFlow provides for training machine learning models, it also provides a powerful tool called TensorBoard, which has an intuitive web interface to help analyze machine learning workflows. TensorBoard supports a profiler tool, which can be used to understand hardware resource consumption and various TensorFlow operations in your machine learning model. It enables metrics and visualizations to help identify performance bottlenecks in your training pipeline.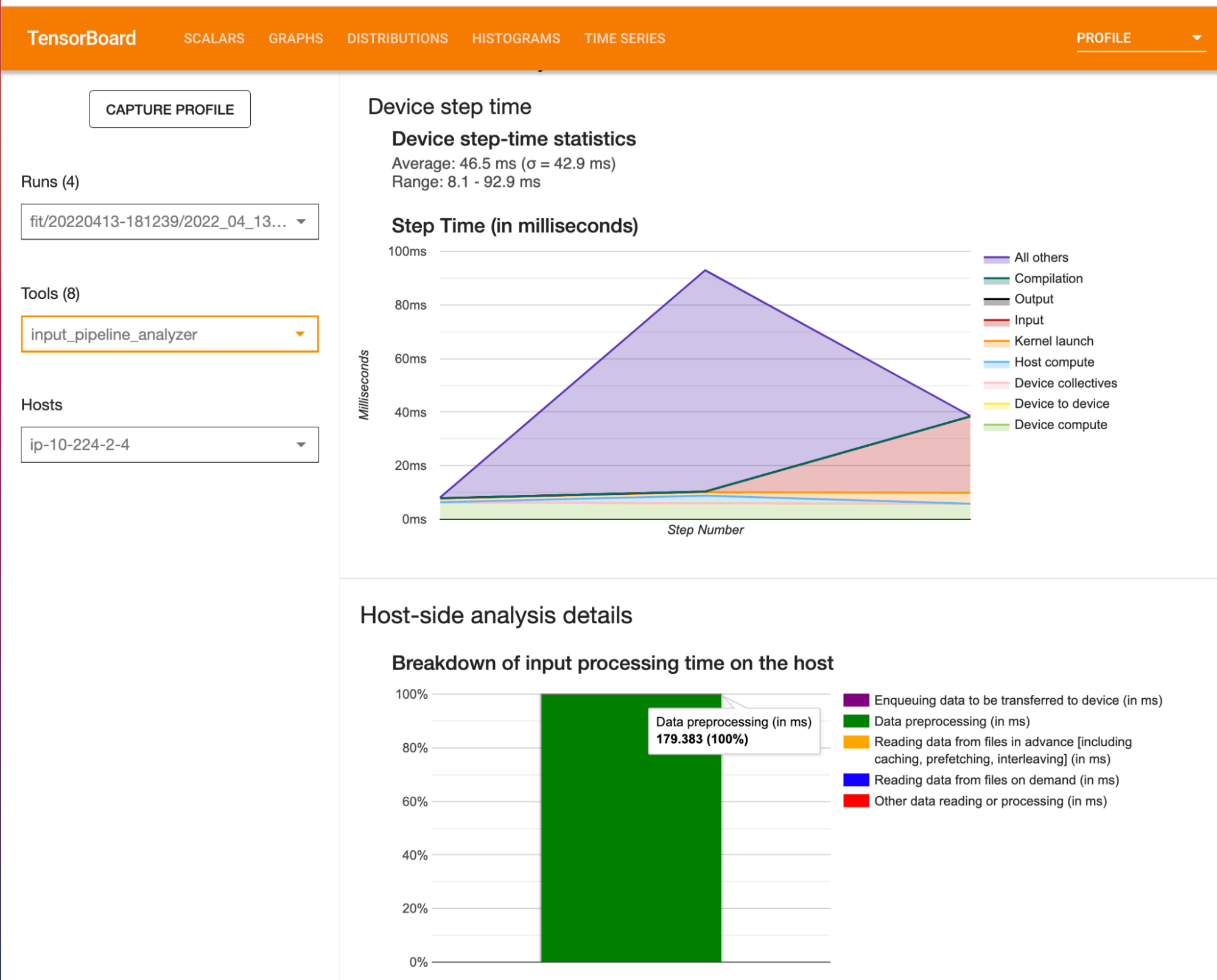 Figure 2. The profiler tool in TensorBoard (Click to enlarge)
Figure 2. The profiler tool in TensorBoard (Click to enlarge)By using the TensorBoard profiler, we observe in the training pipeline that data preprocessing on the CPU takes a significant amount of processing time.
Speeding Up Feature Extraction with Rust
The data preprocessing part of the pipeline, which is equivalent in this case to feature extraction, consists of reading the text file into memory, performing some data transformation operations and outputting a feature vector of integers for each file. There is an opportunity to speed up the feature extraction part of the pipeline by replacing the Python implementation with Rust. The Rust programming language and compiler ensures memory safety in programs at compile time, without resorting to managed memory and the overhead of a Garbage Collector. This is essential for writing secure code that is expected to run with strong memory and performance requirements, on a client machine, while working on untrusted and potentially malicious data. After implementing the feature extraction (FX) logic in Rust, it is then compiled and the resulting library is packaged in a Python package. This package can be easily imported into our Python code for use, replacing the original Python FX code in the Tensorflow pipeline. When the Rust FX Python package is used, the following occurs:
- The package takes the input data in Python.
- It passes the input data to the compiled Rust library.
- Then the calculations occur in machine code.
- Finally, results are passed back to Python.
This solution works well, as it speeds up the feature extraction operations using the Rust compiled library, while also easily integrating into existing Python code as a simple import statement and function call.
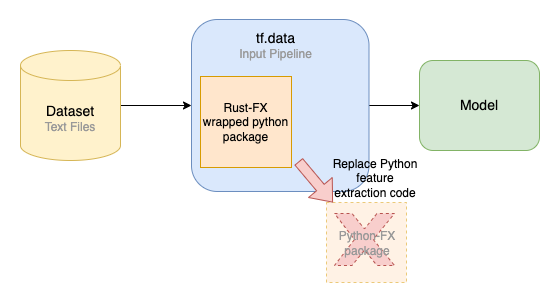 Figure 3. Replacing the Python feature extraction code with Rust
Figure 3. Replacing the Python feature extraction code with RustBy replacing the Python feature extraction code with Rust, total training time decreases from 227 hours to 162 hours.
| Trained On | Training Dataset | Total Training Epochs | Total Training Time |
| MacBook Pro Laptop | 1.9 million text files | 65 | 162 hours |
GPU-enabled Model Training
Amazon Web Services (AWS) provides a large variety of EC2 instances to support different compute needs. The P3 instances fit the requirements for this use case, as P3 instances have NVIDIA V100 Tensor Core GPUs — a GPU is a specialized processing unit that can perform rapid mathematical operations, making it ideal for machine learning — and are set up with CUDA, which can accelerate TensorFlow model training on GPUs. Specifically, a p3.8xlarge instance has a large amount of CPU memory and multiple GPUs, providing opportunities to speed up model training.
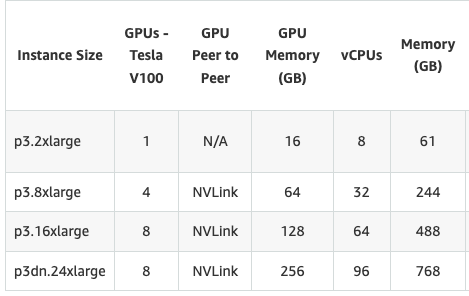 Figure 4. Amazon EC2 P3 instance product details (Source: https://aws.amazon.com/ec2/instance-types/p3/)
Figure 4. Amazon EC2 P3 instance product details (Source: https://aws.amazon.com/ec2/instance-types/p3/)Setting up a GPU-enabled compute environment to work correctly with TensorFlow can be a challenging process, as it can require non-trivial modifications and installs to address version mismatching between the OS, NVIDIA drivers and CUDA libraries. However, using Docker makes these types of modifications to the instance unnecessary. Docker is an open platform for developing, shipping and running applications in a container-based environment, reducing effort and risk of problems with trying to set up application dependencies directly on an instance. Specifically, a public TensorFlow-NVIDIA Docker image is used on the P3 instance. With everything working as expected within the Docker environment, modifying NVIDIA drivers or CUDA libraries on the instance is not required.
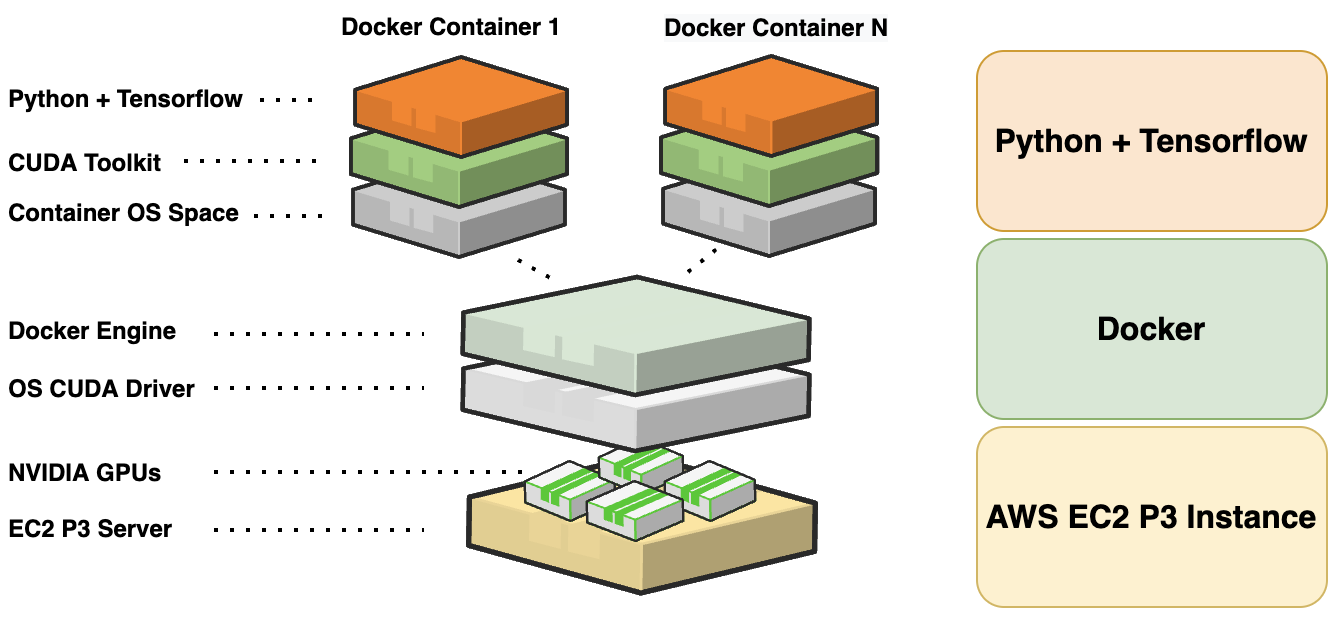 Figure 5. Using Docker in a container-based environment
Figure 5. Using Docker in a container-based environmentGPU Training Results
With the P3 instance configured properly, it’s a matter of copying the dataset and the same TensorFlow code executed on the Mac laptop onto the P3 instance and running the full model training pipeline on a Docker container. Results show a large improvement in total training time, from 163 hours down to 44 hours, as the TensorFlow code accelerates model training by running on the GPU-enabled P3 instance.
| Trained On | Training Dataset | Total Training Epochs | Total Training Time |
p3.8xlarge | 1.9 million text files | 65 | 44 hours |
Prefetching and Caching for Optimized TensorFlow Data Performance
In addition to speeding up training by running on a GPU, TensorFlow provides configuration options that can help build more efficient data pipelines as part of the model training process. The tf.data API provides two important methods that can be used to make sure I/O does not become a bottleneck during model training: prefetch and cache. Prefetching overlaps data preprocessing and model execution while training. Specifically, while a model executes training at the current step, the input pipeline reads the data for the next step. The prefetch transformation reduces total training time by taking advantage of opportunities to do overlapping work.
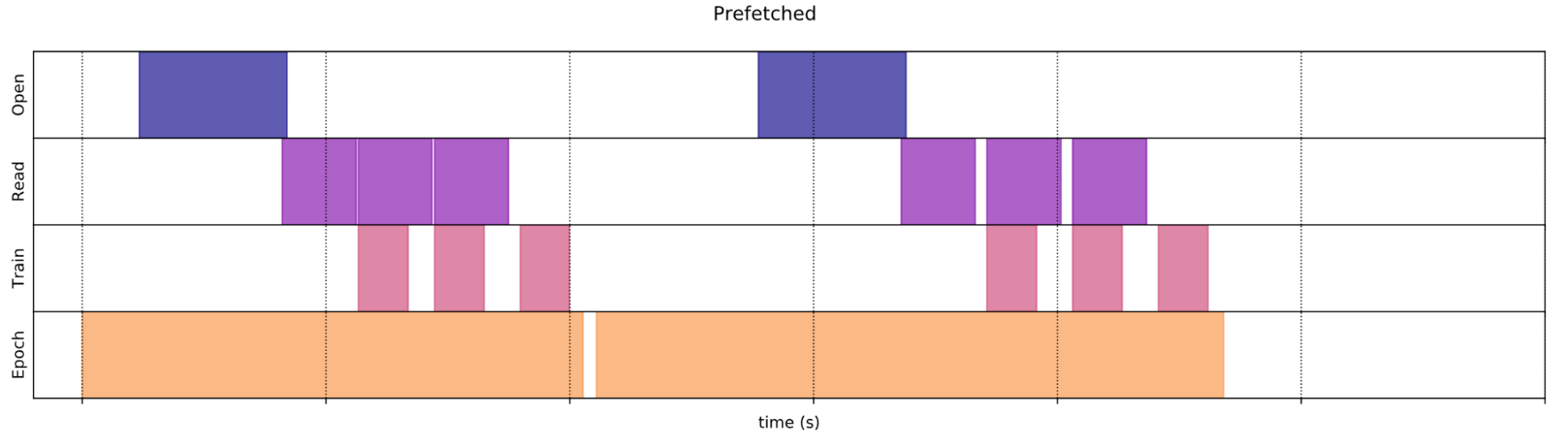 Figure 6. Prefetching data performance (Source: https://www.tensorflow.org/guide/data_performance#prefetching)
Figure 6. Prefetching data performance (Source: https://www.tensorflow.org/guide/data_performance#prefetching)Caching keeps data in memory after it's loaded off disk. This ensures the dataset does not become a bottleneck while training the model. It is important to note that for caching to work optimally in TensorFlow, the total CPU memory of the computer should be larger than the total size of the training dataset.
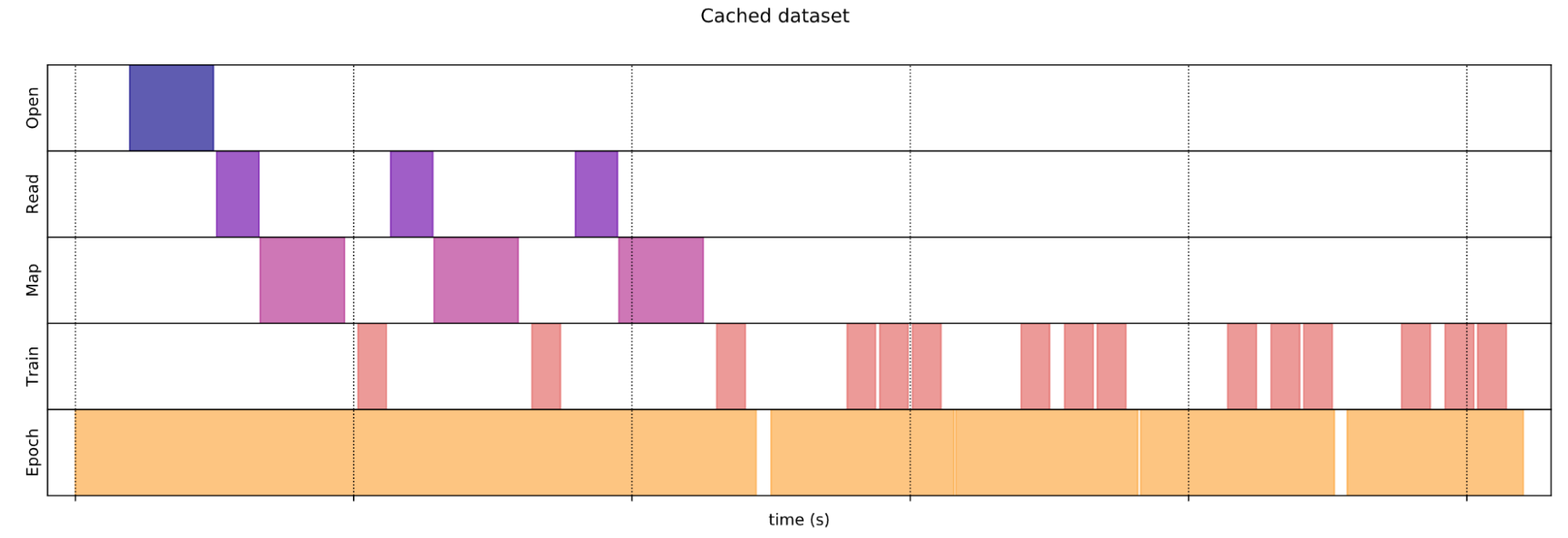 Figure 7. Caching data performance (Source: https://www.tensorflow.org/guide/data_performance#caching)
Figure 7. Caching data performance (Source: https://www.tensorflow.org/guide/data_performance#caching)It is simple to update TensorFlow code to use these methods within the tf.data API: train_dataset = train_dataset.cache().prefetch(buffer_size=tf.data.AUTOTUNE) Note: The optimal number of elements to prefetch() should be greater than or equal to the number of batches consumed by a single training step. TensorFlow tf.data API provides a tf.data.AUTOTUNE flag that can be used to tune the prefetch value dynamically at runtime. After applying these changes and retraining the model, results show another large improvement in training time, from 44 hours down to 6 hours.
| Trained On | Training Dataset | Total Training Epochs | Total Training Time | First Epoch Training Time | Average Training Time per Epoch (2-65)
|
p3.8xlarge | 1.9 million text files | 65 | 6 hours | 40 minutes
| 5 minutes |
Notice that every epoch after the first is extremely fast. This is due to caching. During the first epoch, the entire training dataset is loaded into CPU memory, and feature extraction is performed on the data. For all subsequent epochs, the GPU immediately runs on the training steps on the already processed data (feature vector).
Parallel Model Training
In addition to having a large amount of CPU memory, a major advantage of running on the p3.8xlarge instance is that it has four GPUs. With multiple GPUs on the instance, model training runs in parallel, with each run having a different set of hyperparameters. This reduces overall model development process time by enabling multiple models to be trained in the same six-hour window instead of having to wait for each model training run to complete before launching the next.
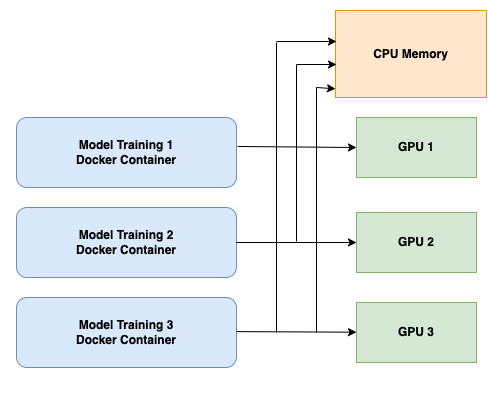 Figure 8. Simplified view of parallel model training across multiple GPUs. The same CPU memory is shared by every model training container. Note that only three of the four instance GPUs are used. This is due to constraints on the instance’s total amount of CPU memory available for caching relative to the size of our training dataset.
Figure 8. Simplified view of parallel model training across multiple GPUs. The same CPU memory is shared by every model training container. Note that only three of the four instance GPUs are used. This is due to constraints on the instance’s total amount of CPU memory available for caching relative to the size of our training dataset.Training Speed Improvements: The Journey in Numbers
Figure 9 is a plot showing the time needed to fully train a single model compared across the incremental improvement made to the training workflow:
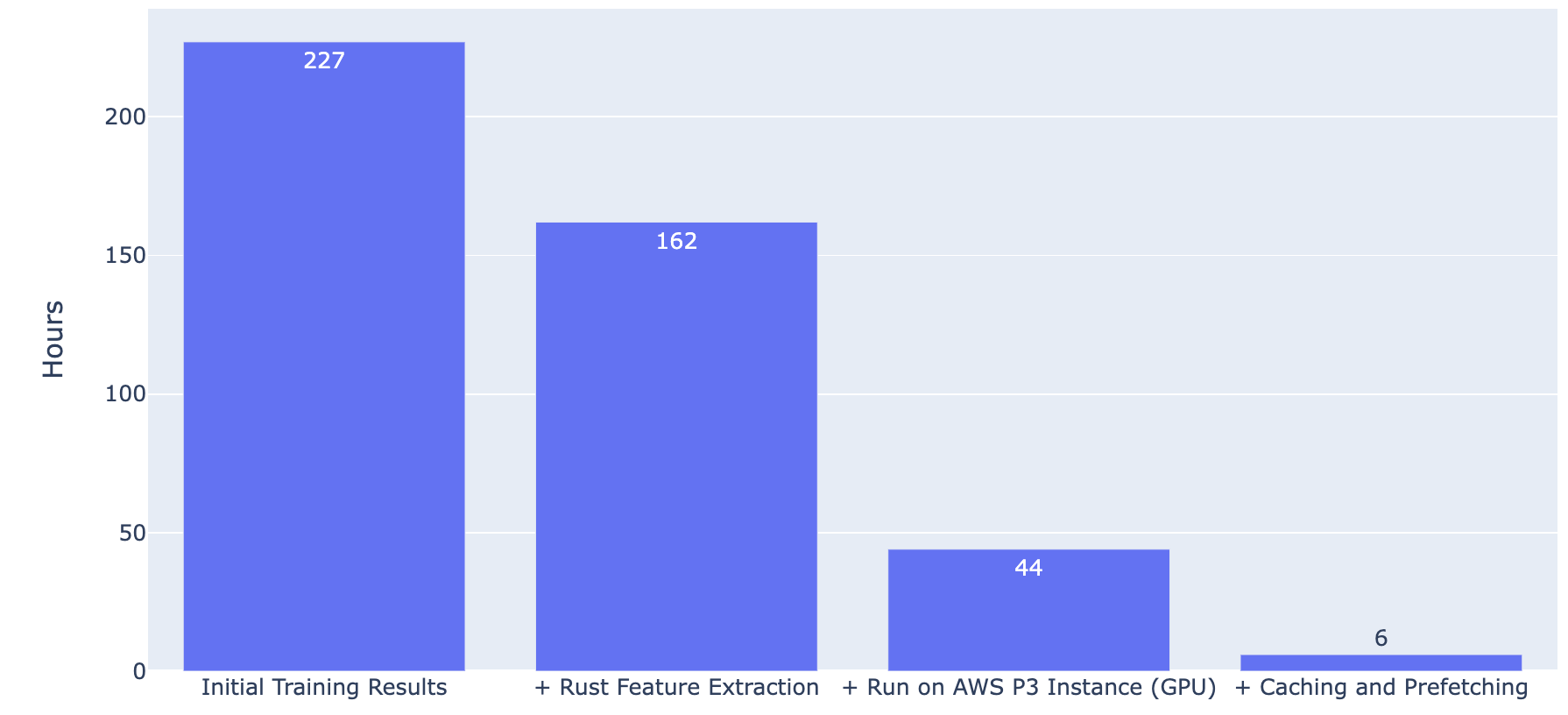 Figure 9. Note that Parallel Model Training is not included in this plot, as it does not affect a single model’s training time, even though it improves total model development time by allowing for multiple runs in parallel.
Figure 9. Note that Parallel Model Training is not included in this plot, as it does not affect a single model’s training time, even though it improves total model development time by allowing for multiple runs in parallel.We can see a significant drop in training time for every improvement made on the journey to a faster model training pipeline.
Conclusion
The steps taken to achieve faster model training for the TensorFlow model are:
- Replacing Python feature extraction code with Rust
- Using an AWS EC2 P3 instance with Docker to accelerate model training on GPUs
- Adding caching and prefetching to our TensorFlow code
- Running multiple model training runs in parallel, leveraging the multiple GPUs available on a p3.8xlarge instance
This journey to faster model training provides a template for accelerated training on any new TensorFlow model developments moving forward. With the model trained and tested, it is now ready for the production pipeline. CrowdStrike has developed tools for converting TensorFlow models into Rust, enabling our models to be safely used with fast inference time and small memory footprint within the CrowdStrike Falcon® sensor environment.
For more information on how CrowdStrike combines the benefits of TensorFlow model training with Rust for model inference, see Building on the Shoulders of Giants: Combining TensorFlow and Rust and Development Cost of Porting TensorFlow Models to Pure Rust. Special thanks to CrowdStrike Senior Rust Software Engineer Joey Hu who assisted with article draft review and Rust feature extraction work.
References
- https://www.TensorFlow.org/guide/data
- https://www.TensorFlow.org/guide/data_performance
- https://www.TensorFlow.org/guide/data_performance_analysis
- https://www.TensorFlow.org/install/docker
- https://www.TensorFlow.org/guide/profiler
- https://aws.amazon.com/ec2/instance-types/p3/
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
Additional Resources
- Learn more about the CrowdStrike Falcon®® platform by visiting the product webpage.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of Falcon Prevent™ today.

