




![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1)










































Deep learning models have undoubtedly achieved astonishing performance in various fields of machine learning, such as natural language processing, voice recognition and computer vision. The impressive learning capabilities that deep models are known for are shadowed only by the large amounts of computational power required to accomplish certain tasks. This becomes a major drawback when the systems used (smartphone, tablet, laptop) cannot satisfy the requirements (space, time and sometimes both). This challenge led to the approach of first training and performing hyperparameter tuning using known deep learning frameworks (e.g., TensorFlow, PyTorch, Caffe), and then reimplementing the optimal version of these models afterward, in a low-level language, to speed up the prediction process.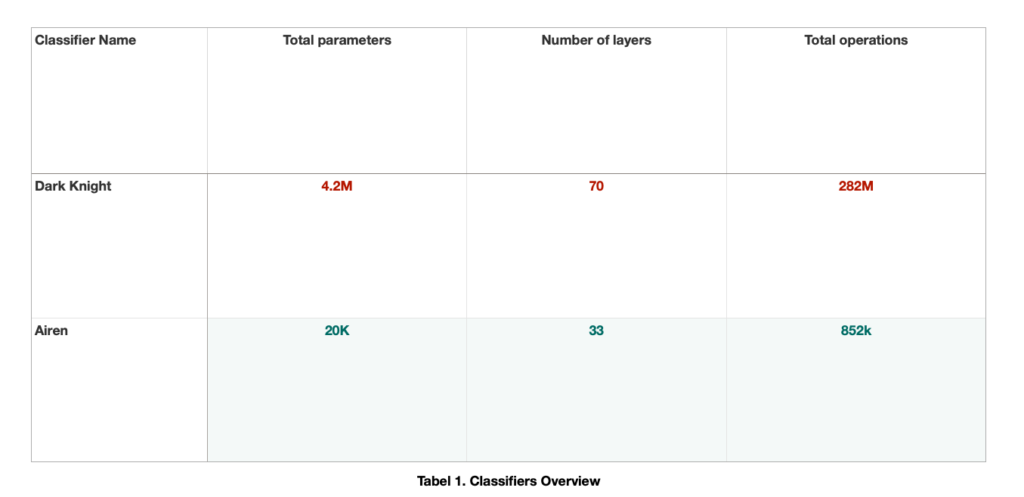
In this approach, we use Rust as the inference tool for trained models in TensorFlow to highlight several additional benefits, including the code size, the build complexity and the performance (memory- and time-related). Also, it is paramount to notice that transitioning to a leaner Rust engine for inference purposes allows us to deploy models more quickly, without having to introduce a complex dependency to our models in production. In this blog, we share our perspectives on combining these two powerful tools to boost both memory performance and speed capability.
Background
TensorFlow is an open-source deep-learning framework introduced in 2011 by developers from Google Brain. Even from its release, it managed to deliver a clean Python API to the end user, while running a C++ engine behind the curtains. With the ever-increasing popularity of this field and its corresponding state-of-the-art solutions, it quickly became a must-know library among machine learning enthusiasts, focusing on two main aspects: training and inference functionalities. Two important advantages that TensorFlow has are represented by its continuous integration with the latest developments in various subfields of artificial intelligence (e.g., natural language processing, computer vision, voice recognition) and its remarkable ease of use for the end user. Rust is a low-level programming language designed with performance in mind, solving one major issue of today’s projects: concurrency problems. Even though it shares the focus on performance with C++, it raised the bar even higher, featuring memory efficiency without the need to deploy an actual garbage collector to achieve that. Despite being a relatively new language (2010), Rust gained a lot of affection among developers for its beautiful API, its extensive documentation and its integrated package manager (and many other features), winning "the most loved programming language" title in the Stack Overflow Developer Survey from 2016 onward.Assessment
In order to assess the performance of these tools and give a fair, unbiased verdict, two internal neural classifiers were used as benchmarks. The first one is our classifier for malicious URLs (code name “Dark Knight”), a model that alerts the end user if a given URL is malicious or not right on the spot, preventing the same user from accessing unreliable websites and having their personal data stolen as a consequence. The second model assessed for performance (code name “Airen”) was designed to detect suspicious file renames that happen as a result of ransomware-like behavior, providing another opportunity to catch and further analyze potential ransomware.Without going into details about the internal structure of each classifier, we highlight their main characteristics — Airen is a model that works at the character level, while Dark Knight goes a little deeper, analyzing a word's context as well (Table 1).
Time Performance
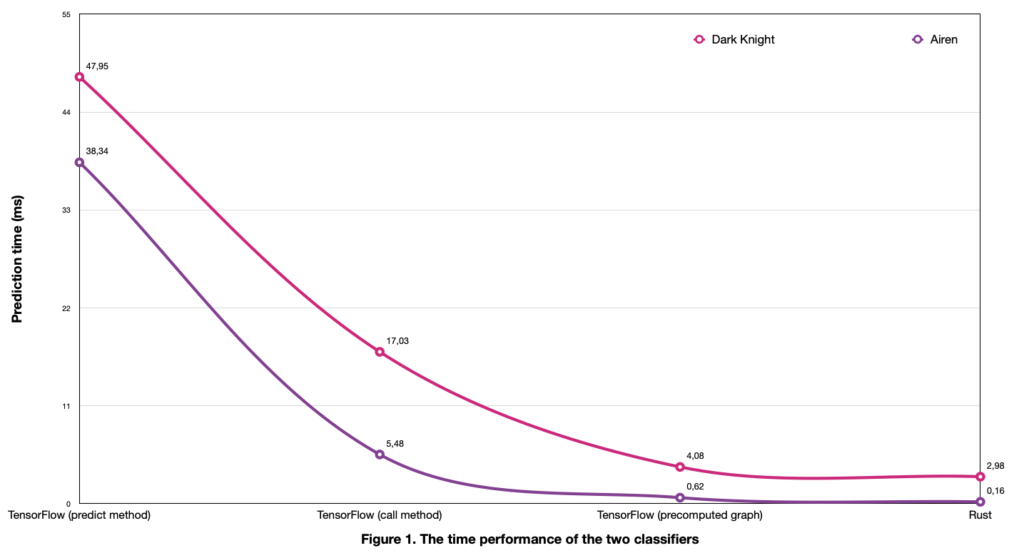
Similar to how TensorFlow acts as a wrapper for the C++ code that fuels this framework, we created a Python wrapper over Rust. The logic behind this step is to account for possible overhead caused by preparing the inputs, calling the actual backend functions and returning from them (although we assume these should be negligible). TensorFlow offers two distinct ways to predict based on a trained model: a predict method and a call method. While the former should be the appropriate solution, several issues involving memory leaks have been reported. A known solution to speed up the prediction in this case is to decorate the call method with @tf.function, meaning that the Python code will be replaced by a static computational graph in a lazy execution fashion, overloading the eager functionality. The time was measured from an end-to-end perspective, from the feature extractor step and up to the actual prediction, running on multiple samples and averaging the execution times. Observation: The loading times of the models were discarded when measuring the performance, as they are dependent on their internal structures and their corresponding initialization phase (i.e., TensorFlow models contain more information than it is required by the inference purpose so it would not have been an apples-to-apples comparison). As can be easily seen in Figure 1 below, the predict method performed worst of all of the methods tested, showing a discrepancy that could point exactly to the previously stated issues known in TensorFlow community. The call method alone achieved a substantial boost in performance in both cases, from 38.34 ms to 5.48 ms (-85.6%) for Airen, and from 47.95 ms to 17.03 ms (-64.4%) for Dark Knight. For the final comparison between the two tools, the precomputed graph method from TensorFlow was preferred (as it was the most efficient TensorFlow solution). While our Python library using Rust as a backend achieved an impressive reduction of 27% in the case of Dark Knight, Airen attained an astonishing time decrease of up to 74.2% (Figure 1). These spectacular numbers alone show a compelling reason to convert TensorFlow models to Rust in order to benefit from a boost in performance while speeding up the inference process.
Memory Performance
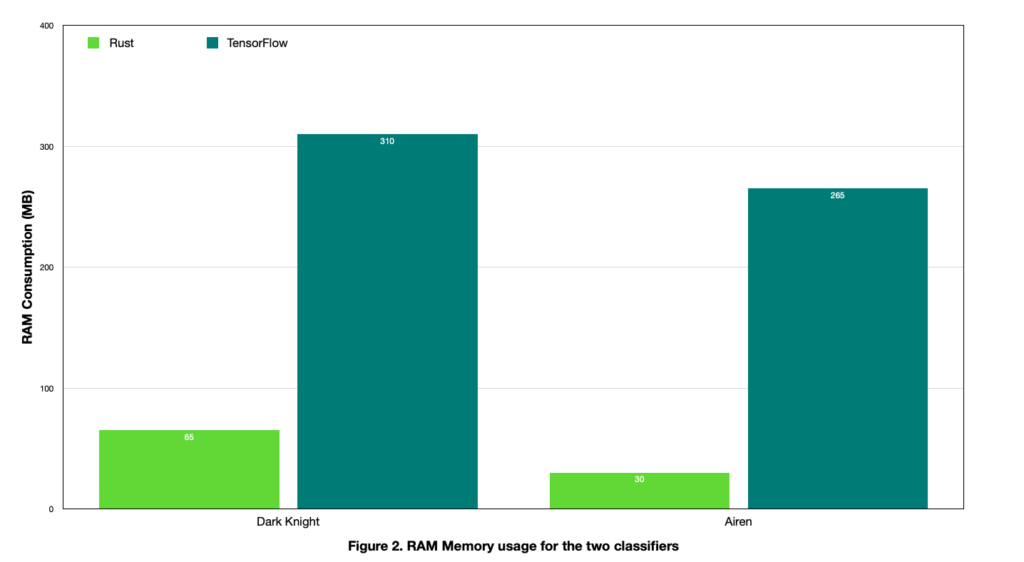
After showing this impressive performance increase in prediction time, we wanted to evaluate the memory performance as well. Our discoveries were incredible — the peak memory usage while running the Dark Knight classifier decreased from 310 MB to just 65 MB, a huge drop of 79%. Similarly, Airen achieved an even more impressive reduction of 89%, from 265 MB to only 30 MB RAM consumption (Figure 2). Even though memory is not a big concern on powerful machines that run on the cloud/edge, it is a critical resource on workstations and also on more limited devices such as smartphones, tablets and personal laptops. These improvements allow multiple models to run directly on almost any device, providing an additional layer of security (especially when a server connection cannot be established due to internet issues), without the need to sacrifice the performance. Observations:- We could have improved memory performance even further by removing numpy from our wrapper and using lists instead. The estimated reduction, as measured locally, would be around 20-25 MB.
- The reason why TensorFlow is so RAM-consuming is because it needs to import the TensorFlow library, which accounts for an enormous amount of memory — 250 MB.
A Powerful Combination
As shown in our comparison, Rust is a programming language that proved to be a powerful tool in itself, in the right hands. Even so, TensorFlow still remains an impressive instrument for the deep learning community. It provides an up-to-date framework, for both enthusiasts and scientists, that can be used to design state-of-the-art solutions for a variety of today’s problems. Our comparison seeks not to state that one tool is better than the other, but to show how professionals can combine their functionalities. One could very easily design and train a custom model using TensorFlow, and then transition to Rust at inference in order to achieve a remarkable boost in performance. TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc. Rust and the Rust logo are trademarks of the Mozilla Foundation.Additional Resources
- Learn about recent intrusion trends, adversary tactics and highlights of notable intrusions in the 2020 Threat Hunting Report.
- Understand the trends and themes that we observed while responding to and remediating incidents around the globe in 2020 — download the latest CrowdStrike Services Cyber Front Lines Report.
- Learn more about the CrowdStrike Falcon® platform by visiting the product webpage.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of Falcon Prevent™ today.


