





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



















































This blog was originally published Sept. 28, 2017 on humio.com. Humio is a CrowdStrike Company.
Assume that you have a 1GB text you want to search. A typical SSD lets you read on the order of 1GB/s, which means that you can copy the file contents from disk into memory at that speed. Next, you will then need to scan through that 1GB of memory using some string search algorithm.  If you try to run a plain string search (
If you try to run a plain string search (memmem) on 1GB, you realize that it also comes at a cost. A decent implementation of memmem will do ~10GB/s, so it adds another 1/10th of a second to your result to search through 1GB of data. Total time: 1.1 second (or 0.9GB/s).  Now, what if we compress the input first? Imagine for simplicity that the input compresses 10x using
Now, what if we compress the input first? Imagine for simplicity that the input compresses 10x using lz4 to 0.1GB (on most workloads we see 5–10x compression). It takes just 0.1 second to read in 0.1GB at 1GB/s from disk into main memory. lz4decompresses at ~2GB/s on a stock Intel i7, or 0.5 second for 1GB. Add search time of 0.1 second to a total of 0.6s for reading from disk and decompressing, and we can now search through 1GB in just 0.7s (or 1.4GB/s). And all of the above is on a single machine. Who needs clusters? 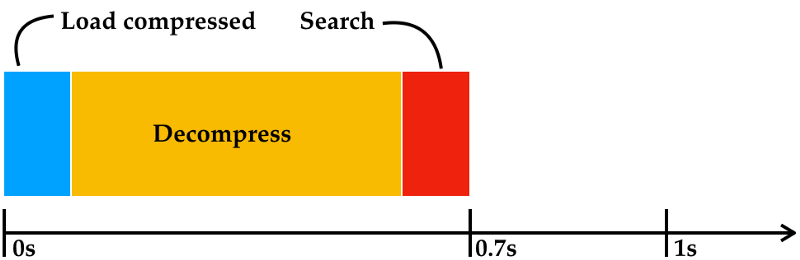 Compressing the input has the obvious additional advantage that the data takes up less disk space, so you can keep more data around and/or keep it for a longer period of time. If, on the other hand, you use a search system that builds an index, then you’re likely to bloat your storage requirements by 5–10x. This is why Humio lets you store 25–100x the data of systems that use indexing. Assuming we’re on a 4-core i7 machine, we can split the compressed data it into four units of work that are individually decompressed and searched on each core for an easy 4x speed up; 1/4th of 0.6 seconds on each core is 0.125s. This gives us a total search time of 0.225 seconds, or 4.4GB/s on a single 4-core machine.
Compressing the input has the obvious additional advantage that the data takes up less disk space, so you can keep more data around and/or keep it for a longer period of time. If, on the other hand, you use a search system that builds an index, then you’re likely to bloat your storage requirements by 5–10x. This is why Humio lets you store 25–100x the data of systems that use indexing. Assuming we’re on a 4-core i7 machine, we can split the compressed data it into four units of work that are individually decompressed and searched on each core for an easy 4x speed up; 1/4th of 0.6 seconds on each core is 0.125s. This gives us a total search time of 0.225 seconds, or 4.4GB/s on a single 4-core machine.  But we can do better. All of the above assumes that we work in main memory, which is limited by a theoretical ~50GB/s bandwidth on a modern CPU, in practice we see ~25GB/s. Once data is on the CPU’s caches it can be accessed even faster. The downside is that the caches are rather small. The level-2 cache for instance is 256kbytes. In the previous example, by the time the decompression of 1/4 of 1GB is done, the beginning of those 256MB have long been evicted from the cache. So what if we move the data onto the level-2 cache in little compressed chunks, so that their decompression also fits in the same cache, and then search in an incremental way? Memory-accesses on the level-2 cache are ~10x faster than main memory, so this would let us speed up the decompress-and-search phase by an order of magnitude. To achieve this, we preprocess the input by splitting the 1GB into up to 128k chunks that are individually compressed. Adding all this up for a search of 1GB to 0.1s for read-from-disk, 0.004s main-to-core 0.1GB @ 25GB/s, and blazing 10x at 0.0125s to decompress-and-search, for a total of 0.1265 seconds reaching 7.9GB/s.
But we can do better. All of the above assumes that we work in main memory, which is limited by a theoretical ~50GB/s bandwidth on a modern CPU, in practice we see ~25GB/s. Once data is on the CPU’s caches it can be accessed even faster. The downside is that the caches are rather small. The level-2 cache for instance is 256kbytes. In the previous example, by the time the decompression of 1/4 of 1GB is done, the beginning of those 256MB have long been evicted from the cache. So what if we move the data onto the level-2 cache in little compressed chunks, so that their decompression also fits in the same cache, and then search in an incremental way? Memory-accesses on the level-2 cache are ~10x faster than main memory, so this would let us speed up the decompress-and-search phase by an order of magnitude. To achieve this, we preprocess the input by splitting the 1GB into up to 128k chunks that are individually compressed. Adding all this up for a search of 1GB to 0.1s for read-from-disk, 0.004s main-to-core 0.1GB @ 25GB/s, and blazing 10x at 0.0125s to decompress-and-search, for a total of 0.1265 seconds reaching 7.9GB/s.  But what if the 1GB file contents is already in the operating system’s file system cache? If it was recently written, or if this is the second time around doing a similar search.The loading the file contents would be instantaneous, and the entire processing would be just 0.0265 seconds, or 37GB/s. Loading data from disk can be done concurrently with processing data, so the loading and processing can overlap in time. Notice that we’re now again dominated by I/O (the blue bar above is wider than the other ones combined), which is why Humio searches faster the better the input compresses. If you search more than a few GBs, then processing is essentially limited by the speed at which we can load the compressed data from disk. To enable even faster searches you simply employ multiple machines. The problem is trivially parallelizable, so to be searching at 100GB/s would just need 3 machines the likes of a desktop i7. The beauty is that this generalizes not just to search, but many other data processing problems which can be expressed in Humio’s query language. Whatever processing is presented the entire input; which makes it easy to extract data and do aggregations such as averages, percentiles, count distinct, etc.
But what if the 1GB file contents is already in the operating system’s file system cache? If it was recently written, or if this is the second time around doing a similar search.The loading the file contents would be instantaneous, and the entire processing would be just 0.0265 seconds, or 37GB/s. Loading data from disk can be done concurrently with processing data, so the loading and processing can overlap in time. Notice that we’re now again dominated by I/O (the blue bar above is wider than the other ones combined), which is why Humio searches faster the better the input compresses. If you search more than a few GBs, then processing is essentially limited by the speed at which we can load the compressed data from disk. To enable even faster searches you simply employ multiple machines. The problem is trivially parallelizable, so to be searching at 100GB/s would just need 3 machines the likes of a desktop i7. The beauty is that this generalizes not just to search, but many other data processing problems which can be expressed in Humio’s query language. Whatever processing is presented the entire input; which makes it easy to extract data and do aggregations such as averages, percentiles, count distinct, etc.
But in the Real World…
Many interesting aggregate computations require non-trivial state (probabilistic percentiles need a sample pool, the hyper-log-log we use for count distinct needs some fancy bitmaps), and these ruin the on-CPU caching somewhat, thereby reducing the performance. Even something as simple as keeping the most recent 200 entries around slows down things. In all honesty, most of the above is more or less wishful thinking. It’s the theoretical limits of an optimal program. For several reasons, we really only get around 6GB/s or 1/6th of the theoretical speed, not ~37GB/s per node that I tallied up above. Trouble is that our system does many other things that end up influencing the outcome, and it is really hard to measure exactly where the problem is at the appropriate level of detail without influencing the outcome. But performance is still decent — and (unfortunately) our customers are asking for more features, not more performance, at present. The system really lends itself to a data processing problem where lots of data is ingested but queries are relatively rare. So it’s a good match for a logging tool: logs arrive continually, they are relatively fast to compress, and few people such as sysops and developers initiate queries. Humio easily sustains a large volume of ingest, we have seen successful single-node deployments taking in +1TB/day; when someone comes around to ask a question, it will use all available processing power (for a short while) for just that single query. In a later post, I’ll get back to how we improve these tradeoffs using stream processing to maintain ‘views’ that are readily available for retrieval.

