





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



















































This blog was originally published Feb. 17, 2020 on humio.com. Humio is a CrowdStrike Company. Humio is built from the ground up to be the most powerful log management system available. It is developed to use all the advantages of today’s modern computing architecture. Our engineers are passionate about optimizing the latest technology, and they won’t stop making performance improvements to ingesting, analyzing, and storing hundreds of terabytes of streaming data in real time.
The query language and the speed of Humio compared to searching logs in Kibana is crazy! Much better experience in my opinion, and makes investigating and caring about logs so much easier. —Kasper Nissen,
Cloud Architect,
Lunar
Humio has a unique index-free architecture that bypasses the requirements of traditional indexed databases, so data is instantly available for dashboard updates, alerts, and searches. And with Humio’s advanced compression, it stores the data with 5-15x (or more) data than traditional index-based log solutions. So how can Humio search an entire petabyte of data and get results in under one second? It uses intelligent filtering and advanced compression to reduce the data set, and then loads all the data into memory to make brute-force search blazing fast.
Humio is so incredibly fast that you can try any query that may or may not give a useful result without feeling you are wasting time. —Niels Ladegaard Beck,
CTO,
BeScord Banking
To see how it works, take a look at how Humio intelligently filters the dataset before performing the search. 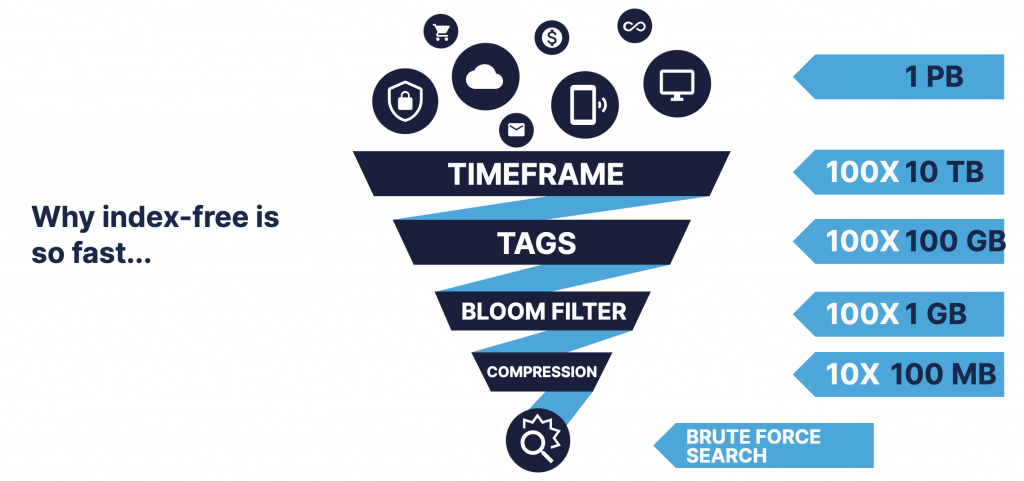 TIMEFRAME: Humio stores all data based on its timestamp, and searches are limited to a given timeframe. If you have 1 PB of data covering a year or more, you can reduce the data set by 100x if your search is limited to a few days. TAGS: The context of the data is stored in lightweight tags — summarizing things like where the data came from or how it is used. These are used to further reduce the data set, by up to 100x in most cases. BLOOM FILTER: Information about ingested data is added to probabilistic
TIMEFRAME: Humio stores all data based on its timestamp, and searches are limited to a given timeframe. If you have 1 PB of data covering a year or more, you can reduce the data set by 100x if your search is limited to a few days. TAGS: The context of the data is stored in lightweight tags — summarizing things like where the data came from or how it is used. These are used to further reduce the data set, by up to 100x in most cases. BLOOM FILTER: Information about ingested data is added to probabilistic
Bloom filters, named for Burton Howard Bloom. These determine with 100% certainty if the results of a search are
not
in a given data set. This eliminates the need to access those data sets, further limiting the data sets that require searching. COMPRESSION: Humio compresses all data stored on disk by 5-15x or more. This further reduces the data Humio needs to handle with a 10X. Humio moves index-free compressed data to memory, which takes a fraction of the time of uncompressed, indexed data. BRUTE FORCE SEARCH: Humio performs all this filtering, transferring, and decompressing in a fraction of a few hundredths of a second. It then performs a brute-force search on the relevant data. A brute-force search on the remaining 100 MB of data typically takes less than a few hundred milliseconds.
Everything paled compared to Humio... I’m still astonished on a regular basis how incredibly fast Humio is. —Simon Stender Boisen, CTO, Lix
For more detail on how Humio’s index-free architecture and brute-force search is fast, read
How Humio leverages Kafka and brute-force search to get blazing-fast search results. We’d love to show you what Humio can do for your organization. Schedule a
with one of our product experts, or get started with a

