





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)



















































This blog was originally published Dec. 30, 2019 on humio.com. Humio is a CrowdStrike Company.
Observability. It’s a buzzword that has been making the rounds in the IT Ops, DevOps, and Security Ops space for at least a few years. If your job involves understanding or maintaining the functionality and performance of applications and systems, you’ve heard the term used to describe knowing what’s happening with the components of the system. Observability is an important concept for those responsible for the health of any complex IT infrastructure, and it’s worth making sure we agree on what it means and how to achieve it.
Let’s Start at the Start
I love writing, and one of the things I enjoy is delving into the meaning and origin of words. So I think it’s useful to start with a basic definition. In a general sense, to
something is to watch it carefully with the hope of arriving at a judgment. Something is
observable if it can be seen or watched — like the observable universe. In physics, an observable is a physical property that can be measured directly, like temperature or position. From
observe
and
observable
comes the term
observability
(think “observe-ability”), the
ability
to observe. It describes a property of something, so something is either observable or it isn’t.
1960: Observability and Control Theory
In the technical world, the term
observability
has its roots in Control Theory, a field of mathematics for dynamic engineering and mechanical systems. A large system can be optimized if the right controls are in place, and those controls can work only if they know how the system is performing. In a system, observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs.
In 1960,
introduced the term to describe how well a system can be measured by its outputs. In mechanical systems, sensors and detectors measure the output to inform controls that are in place.
2013: The Twitter Observability Team Describes Its Mission
In September 2013, engineers at Twitter wrote a blog post called
Observability at Twitter. It’s one of the first times the term observability was used in the context of IT systems. It’s especially noteworthy that it is used at Twitter, one of the platforms with the most real-time event data in the world. "Engineers at Twitter need to determine the performance characteristics of their services, the impact on upstream and downstream services, and get notified when services are not operating as expected," the post states. "It is the Observability team’s mission to analyze such problems with our unified platform for collecting, storing, and presenting metrics. Creating a system to handle this job at Twitter scale is really difficult." The post goes on to explain how they "capture, store, query, visualize and automate this entire process."
2016: The (Four) Pillars of Observability at Twitter
A few years later,
from the Observability Engineering team at Twitter created a blog post called
Observability at Twitter: technical overview, part I, where he outlined four pillars of their team’s charter. This is one of the early instances of Observability Pillars being described by data types. Note that Alerting and Visualizations were included, even though they are outputs of data, rather than data types themselves. The post states: "The Observability Engineering team at Twitter provides full-stack libraries and multiple services to our internal engineering teams to monitor service health, alert on issues, support root cause investigation by providing distributed systems call traces, and support diagnosis by creating a searchable index of aggregated application/system logs." The post proceeds to outline the four pillars of the team's charter:
- Monitoring
- Alerting/visualization
- Distributed systems tracing infrastructure
- Log aggregation/analytics
2017: The Three Pillars of Observability
In February 2017,
attended the 2017 Distributed Tracing Summit. He was part of a discussion about defining and scoping how tracing helps provide observability. In a blog post called
Metrics, tracing, and logging, he describes how he thought they could probably map out the domain of instrumentation, or observability, as a sort of Venn diagram. He had a think over a coffee break and came up with this.
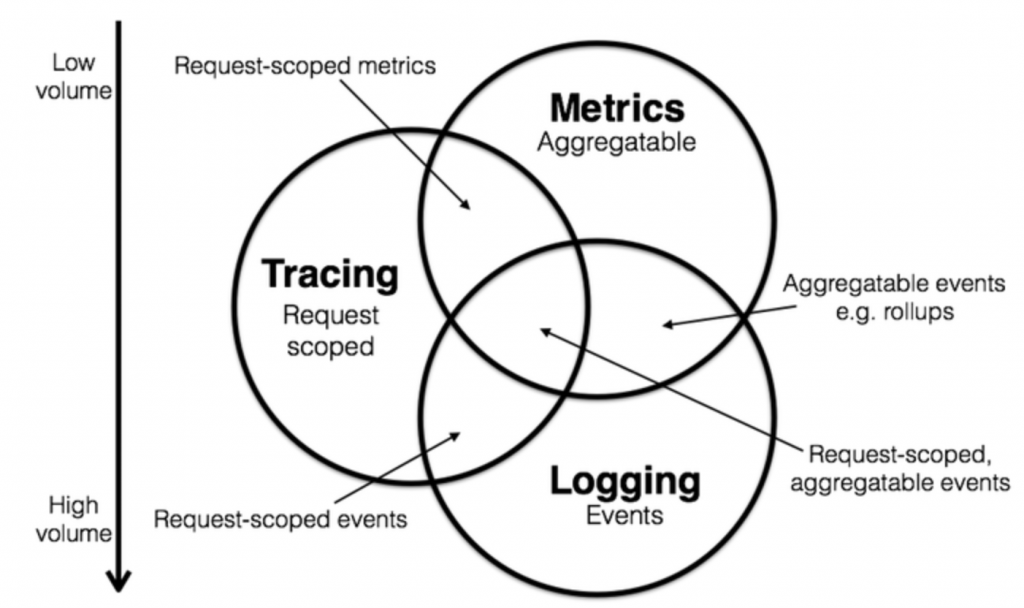 Image source: https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
Image source: https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html2018: The Year of Observability
In 2018, observability and the three pillars of logging, metrics, and tracing became part of the mainstream conversation. In March 2018, QCon added an “Observability” track to the conference, and leaders in the industry began evangelizing the importance of observability. Every company involved in this track described how their company’s products and services provide observability. In June, 2018,
Geeta Schmidt, CEO of Humio, added her thoughts in a Medium article called
Data-Driven Observability & Logs. She points out that simply having tools in place for log management, metrics, and tracing isn’t enough to get value from them. She insists that a cultural shift is needed that values facts and feedback, is data-driven during debugging, and uses this mindset to iterate, improve, and solve problems. In July 2018,
Cindy Sridharan published a definitive book for O’Reilly called Distributed Systems Observability. The book outlines the three pillars of observability, and details which tools to use and when. By the second half of 2018, nearly everyone in the infrastructure systems space claims that if they don’t provide comprehensive observability with their product or service, they at least provide a critical component. As you can see, Humio was included. As 2018 came to a close, cracks began to appear in the model of the three pillars of observability. On September 25, 2018,
Charity Majors, CTO of Honeycomb, warns (in her inimitable way) that describing observability as three pillars limits the discussion. She shared
a series of Tweets where she boldly exclaims “THERE ARE NO THREE PILLARS OF OBSERVABILITY,” adding "and the fact that everybody keeps blindly repeating this mantra (and cargo culting these primitives) is probably why our observability tooling is 10 years behind the rest of our software tool chain." She further states: "it’s the EVENT that is the execution path of your code through the system. It is the correct lens through which to understand your systems from the inside out.” Many in the industry took heed, and began to think of observability apart from the three pillars.
2019: Passionate Debate Ensues
As companies purchased and deployed tools to collect data from each of the three pillars, they found they had access to a lot more system data, but they still didn’t achieve 100% observability of their infrastructure. It turns out that the tools that promised observability couldn’t handle the volume of data coming from terabytes of unstructured data. Engineers had to limit the data they would keep to stay within limits capped by expensive licenses. They found the tools they were using were too slow, due to indexing latency and other issues that made real-time observability impossible. And the new systems were too complicated, with difficult deployment, impractical and expensive maintenance, and interfaces that were inconsistent, hard to learn, and hard to use. Across the industry, tech leaders joined the conversation to redefine observability. In February 2019,
Ben Sigelman, CEO and co-founder of LightStep, fired a shot across the bow with a blog post called
Three Pillars With Zero Answers: A New Scorecard for Observability. He describes how high-cardinality metrics overwhelm systems. He points out that logs become too expensive if you want to ingest, retain, and store the massive volumes of data coming from distributed systems. And traces become impractical if you don’t determine the right samples. Even if all that can be overcome, he points out that
none of that directly addresses a particular pain point, use case, or business need. In August 2019,
Mads Hartmann, Site Reliability Engineer at Glitch, did a deep dive into observability over several months, and published his thoughts in Journey into Observability: Reading material. His takeaway is that you can’t achieve observability simply from the telemetry (the process of recording and transmitting the readings of instruments) your system produces. He proposes an alternative view of observability:
...Observability is all about being able to ask questions of your system and get answers based on the existing telemetry it produces; if you have to re-configure or modify the service to get answers to your questions you haven’t achieved observability yet.
Charity Majors agrees with the direction Mads is heading. In August 2019, she published an article in The New Stack: Observability — A 3-Year Retrospective. In it she leads the challenge to appropriate a new definition for observability:
If we do not appropriate “observability” to denote the differences between known unknowns and unknown-unknowns, between passive monitoring and exploratory debugging, it is not clear what other terms are available to us (and unclear that the same fate will not befall them).
She goes on to suggest that realizing the promise of observability comes from being able to inspect the internal state of your systems and be able to ask any question to understand it.
By using events and passing along the full context, conversely I can ask any question of my systems and inspect its internal state, therefore I can understand any state my system has gotten itself into — even if I have never seen it before, never conceived of it before! I can understand anything that is happening inside my system, any state it may be in — without having to ship new code to handle the state. This is key. This is observability.
2020: Observability (Re)defined
The industry is aligning to the latest thinking, that observability isn’t a feature you can install or a service you can subscribe to. It’s not simply the deployment and collection of three types of data. Observability is something you either have, or you don’t. It only is achieved when you have all the data to answer any question, whether predictable or not. We agree with those that think of it this way:
Observability is when you’re able to understand the internal state of a system from the data it provides, and you can explore that data to answer any question about what happened and why.
I have no doubt that the definition will evolve further.
How Humio Helps Make Your System Observable
At Humio, we believe in the value of data-driven logging and the benefits companies can derive from this in their observability stack. Because the Humio platform can collect any unstructured event data — including logs, metrics, and traces — it makes any system that provides event data observable. With simple pricing and unique product, we are on a mission to bring this value to engineering teams who’ve been struggling until now.
About the Humio Platform
Humio delivers real-time monitoring and investigation capabilities for developers and operations teams. Humio is:
- SCALABLE:
Proprietary time-series database engine efficiently handles multi-TB/day log volumes (one single instance of Humio can ingest more than 1 TB of log volume/day) - FAST:
Real-time streaming capabilities built-in for live query, dashboard capabilities, and alerts. - FLEXIBLE:
Open ingest API and support for open source data shippers and common data formats - EASY TO USE:
Familiar query structure and intuitive web interface that developers and operations teams love to use - AFFORDABLE:
Humio offers the lowest
Total Cost of Ownership
of any major competitor, and has an industry-leading Unlimited Plan.
Key Features
- Humio is available in both On-Premises and Cloud versions
- Streaming queries and dashboards stored in an in-memory state machine for instant data access
- Linear scaling and blazing-fast search speed
- Ad-hoc and historical search with a simple search language
- Live dashboards and shareable dashboard widgets
- Support for multi-tenant infrastructures
- Open API for data ingest and support for open-source log shippers (Logstash and Filebeat) and common log and data formats (Fluentd, Syslog, NGINX, JSON, Kafka, Zeek, and more)
- Alerting integrations with Slack, PagerDuty, VictorOps, OpsGenie, email, and webhooks.
The Humio Unlimited Plan
Humio’s Unlimited Plan gives organizations access to all the data they need to prepare for the unknown. With unlimited log aggregation, real-time search and exploration, and the ability to retain compressed data for longer, Humio minimizes recovery time, and makes it easy to get to the root cause of unexpected issues. Find out more from our website’s
Why Unlimited? page.
Get started by downloading a free 30-day trial version (no credit card required), or requesting a demo.

