





![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1?wid=530&hei=349&fmt=png-alpha&qlt=95,0&resMode=sharp2&op_usm=3.0,0.3,2,0)
















































The State of Kernel Exploitation
The typical write-what-where kernel-mode exploit technique usually relies on either modifying some key kernel-mode data structure, which is easy to do locally on Windows thanks to poor Kernel Address Space Layout Randomization (KASLR), or on redirecting execution to a controlled user-mode address, which will now run with Ring 0 rights.
Relying on a user-mode address is an easy way not to worry about the kernel address space, and to have full control of the code within a process. Editing the tagWND structure or the HAL Dispatch Table are two very common vectors, as are many others.
However, with Supervisor Mode Execution Prevention (SMEP), also called Intel OS Guard, this technique is no longer reliable — a direct user-mode address cannot be used, and other techniques must be employed instead.
One possibility is to disable SMEP Enforcement in the CR4 register through Return-Oriented Programming, or ROP, if stack control is possible. This has been covered in a few papers and presentations.
Another related possibility is to disable SMEP Enforcement on a per-page basis — taking a user-mode page and marking it as a kernel page by making the required changes in the page level translation mapping entries. This has also been talked in at least one presentation, and, if accepted, a future SyScan 2015 talk from a friend of mine will also cover this technique. Additionally, if accepted, an alternate version of the technique will be presented at INFILTRATE 2015, by yours truly.
Finally, a theoretical possibility is being able to transfer execution (through a pointer, callback table, etc) to an existing function that disables SMEP (and thus bypassing KASLR), but then somehow continues to give the attacker control without ROP — nobody has yet found such a function. This would be a type of Jump-Oriented Programming (JOP) attack.
Nonetheless, all of these techniques continue to leverage a user-mode address as the main payload (nothing wrong with that). However, one must also consider the possibility to use a kernel-mode address for the attack, which means that no ROP and/or PTE hacking is needed to disable SMEP in the first place.
Obviously, this means that the function to perform the malicious payload’s work already exists in the kernel, or we have a way of bringing it into the kernel. In the case of a stack/pool overflow, this payload probably already comes with the attack, and the usual tricks have been employed there in order to get code execution. Such attacks are particularly common in true ‘remote-remote’ attacks.
But what of write-what-where bugs, usually the domain of the local (or remote-local) attacker? If we have user-mode code execution available to us, to execute the write-what-where, we can obviously continue using the write-what-where exploit to repeatedly fill an address of our choice with the payload data. This presents a few problems however:
- The write-what-where may be unreliable, or corrupt adjacent data. This makes it hard to use it to ‘fill’ memory with code.
- It may not be obvious where to write the code — having to deal with KASLR as well as Kernel NX. On Windows, this is not terribly hard, but it should be recognized as a barrier nonetheless.
This blog post introduces what I believe to be two new techniques, namely a generic kernel-mode heap spraying technique which results in executable memory, followed by a generic kernel-mode heap address discovery technique, bypassing KASLR.
Big Pool
Experts of the Windows heap manager (called the pool) know that there are two different allocators (three, if you’re being pedantic): the regular pool allocator (which can use lookaside lists that work slightly differently than regular pool allocations), and the big/large page pool allocator.
The regular pool is used for any allocations that fit within a page, so either 4080 bytes on x86 (8 bytes for the pool header, and 8 bytes used for the initial free block), or 4064 bytes on x64 (16 bytes for the pool header, 16 bytes used for the initial free block). The tracking, mapping, and accounting of such allocations is handled as part of the regular slush of kernel-mode memory that the pool manager owns, and the pool headers link everything together.
Big pool allocations, on the other hand, take up one or more pages. They’re used for anything over the sizes above, as well as when the CacheAligned type of pool memory is used, regardless of the requested allocation size — there’s no way to easily guarantee cache alignment without dedicating a whole page to an allocation.
Because there’s no room for a header, these pages are tracked in a separate “Big Pool Tracking Table” (nt!PoolBigPageTable), and the pool tags, which are used to identify the owner of an allocation, are also not present in the header (since there isn’t one!), but rather in the table as well. Each entry in this table is represented by a POOL_TRACKER_BIG_PAGES structure, documented in the public symbols:
1 2 3 4 5 |
lkd> dt nt!_POOL_TRACKER_BIG_PAGES
+0x000 Va : Ptr32 Void
+0x004 Key : Uint4B
+0x008 PoolType : Uint4B
+0x00c NumberOfBytes : Uint4B
|
One thing to be aware of is that the Virtual Address (Va) is OR’ed with a bit to indicate if the allocation is freed or allocated — in other words, you may have duplicate Va’s, some freed, and at most one allocated. The following simple WinDBG script will dump all the big pool allocations for you:
1 2 3 4 5 6 7 8 9 10 |
r? @$t0 = (nt!_POOL_TRACKER_BIG_PAGES*)@@(poi(nt!PoolBigPageTable))
r? @$t1 = *(int*)@@(nt!PoolBigPageTableSize) / sizeof(nt!_POOL_TRACKER_BIG_PAGES)
.for (r @$t2 = 0; @$t2 < @$t1; r? @$t2 = @$t2 + 1)
{
r? @$t3 = @$t0<@$t2>;
.if (@@(@$t3.Va != 1))
{
.printf "VA: 0x%p Size: 0x%lx Tag: %c%c%c%c Freed: %d Paged: %d CacheAligned: %d\n", @@((int)@$t3.Va & ~1), @@(@$t3.NumberOfBytes), @@(@$t3.Key >> 0 & 0xFF), @@(@$t3.Key >> 8 & 0xFF), @@(@$t3.Key >> 16 & 0xFF), @@(@$t3.Key >> 24 & 0xFF), @@((int)@$t3.Va & 1), @@(@$t3.PoolType & 1), @@(@$t3.PoolType & 4) == 4
}
}
|
Why are big pool allocations interesting? Unlike small pool allocations, which can share pages, and are hard to track for debugging purposes (without dumping the entire pool slush), big pool allocations are easy to enumerate. So easy, in fact, that the undocumented KASLR-be-damned API NtQuerySystemInformation has an information class specifically designed for dumping big pool allocations. Including not only their size, their tag, and their type (paged or nonpaged), but also their kernel virtual address!
As previously presented, this API requires no privileges, and only in Windows 8.1 has it been locked down against low integrity callers (Metro/Sandboxed applications). With the little snippet of code below, you can easily enumerate all big pool allocations:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
//
// Note: This is poor programming (hardcoding 4MB).
// The correct way would be to issue the system call
// twice, and use the resultLength of the first call
// to dynamically size the buffer to the correct size
//
bigPoolInfo = RtlAllocateHeap(RtlGetProcessHeap(),
0,
4 * 1024 * 1024);
if (bigPoolInfo == NULL) goto Cleanup;
|
Pool Control
Obviously, it’s quite useful to have all these handy kernel-mode addresses. But what can we do to control their data, and not only be able to read their address?
You may be aware of previous techniques where a user-mode attacker allocates a kernel-object (say, an APC Reserve Object), which has a few fields that are user-controlled, and which then has an API to get its kernel-mode address. We’re essentially going to do the same here, but rely on more than just a few fields. Our goal, therefore, is to find a user-mode API that can give us full control over the kernel-mode data of a kernel object, and additionally, to result in a big pool allocation.
This isn’t as hard as it sounds: anytime a kernel-mode component allocates over the limits above, a big pool allocation is done instead. Therefore, the exercise reduces itself to finding a user-mode API that can result in a kernel allocation of over 4KB, whose data is controlled. And since Windows XP SP2 and later enforce kernel-mode non-executable memory, the allocation should be executable as well.
Two easy examples may popup in your head:
- Creating a local socket, listening to it, connecting from another thread, accepting the connection, and then issuing a write of > 4KB of socket data, but not reading it. This will result in the Ancillary Function Driver for WinSock (AFD.SYS), also affectionally known as “Another F*cking Driver”, allocating the socket data in kernel-mode memory. Because the Windows network stack functions at DISPATCH_LEVEL (IRQL 2), and paging is not available, AFD will use a nonpaged pool buffer for the allocation. This is great, because until Windows 8, nonpaged pool is executable!
- Creating a named pipe, and issuing a write of > 4KB of data, but not reading it. This will result in the Named Pipe File System (NPFS.SYS) allocating the pipe data in a nonpaged pool buffer as well (because NPFS performs buffer management at DISPATCH_LEVEL as well).
Ultimately, #2 is a lot easier, requiring only a few lines of code, and being much less inconspicuous than using sockets. The important thing you have to know is that NPFS will prefix our buffer with its own internal header, which is called a DATA_ENTRY. Each version of NPFS has a slightly different size (XP- vs 2003+ vs Windows 8+). I’ve found that the cleanest way to handle this, and not to worry about offsets in the final kernel payload, is to internally handle this in the user-mode buffer with the right offsets. And finally, remember that the key here is to have a buffer that’s at least the size of a page, so we can force the big pool allocator.
Here’s a little snippet that keeps all this into account and will have the desired effects:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | UCHAR payLoad; |
Now all we need to know is that NPFS uses the pool tag ‘NpFr’ for the read data buffers (you can find this out by using the !pool and !poolfind commands in WinDBG). We can then change the earlier KASLR-defeating snippet to hard-code the pool tag and expected allocation size, and we can instantly find the kernel-mode address of our buffer, which will fully match our user-mode buffer.
Keep in mind that the “Paged vs. Nonpaged” flag is OR’ed into the virtual address (this is different from the structure in the kernel, which tracks free vs. allocated), so we’ll mask that out, and also make sure you align the size to the pool header alignment (it’s enforced even for big pool allocations). Here’s that snippet, for x86 Windows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//
// Based on pooltag.txt, we're looking for the following:
// NpFr - npfs.sys - DATA_ENTRY records (r/w buffers)
//
for (entry = bigPoolInfo->AllocatedInfo;
entry < (PSYSTEM_BIGPOOL_ENTRY)bigPoolInfo +
bigPoolInfo->Count;
entry++)
{
if ((entry->NonPaged == 1) &&
(entry->TagUlong == 'rFpN') &&
(entry->SizeInBytes == ALIGN_UP(PAGE_SIZE + 44,
ULONGLONG)))
{
printf("Kernel payload @ 0x%p\n",
(ULONG_PTR)entry->VirtualAddress & ~1 +
PAGE_SIZE);
break;
}
}
|
And here’s the proof in WinDBG:
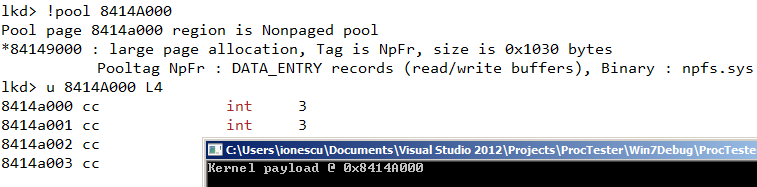
Voila! Package this into a simple “kmalloc” helper function, and now you too, can allocate executable, kernel-mode memory, at a known address! How big can these allocations get? I’ve gone up to 128MB without a problem, but this being non-paged pool, make sure you have the RAM to handle it. Here’s a link to some sample code which implements exactly this functionality.
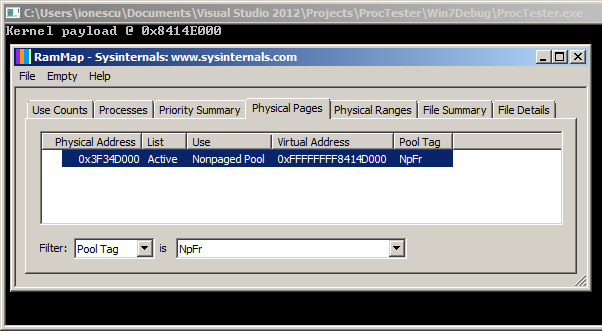
An additional benefit of this technique is that not only can you get the virtual address of your allocation, you can even get the physical address! Indeed, as part of the undocumented Superfetch API that I first discovered and implemented in my meminfo tool, which has now been supplanted by the RAMMap utility from SysInternals, the memory manager will happily return the pool tag, virtual address, and physical address of our allocation.
Here’s a screenshot of RAMMap showing another payload allocation and its corresponding physical address (note that the 0x1000 difference is since the command-line PoC biases the pointer, as you saw in the code).
Next Steps
Now, for full disclosure, there are a few additional caveats that make this technique a bit less sexy in 2015 — and why I chose to talk about it today, and not 8 years ago when I first stumbled upon it:
1) Starting with Windows 8, nonpaged pool allocations are now non-executable. This means that while this trick still lets you spray the pool, your code will require some sort of NX bypass first. So you’ve gone from bypassing SMEP to bypassing kernel-mode NX.
2) In Windows 8.1, the API to get the big pool entries and their addresses is no longer usable by low-integrity callers. This significantly reduces the usefulness in local-remote attacks, since those are usually launched through sandboxed applications (Flash, IE, Chrome, etc) and/or Metro containers.
Of course, there are some ways around this — a sandbox escape is often used in local-remote attacks anyway, so #2 can become moot. As for #1, some astute researchers have already figured out that NX was not fully deployed — for example, Session Pool allocations, are STILL executable on newer versions of Windows, but only on x86 (32-bit). I leave it as an exercise to readers to figure out how this technique can be extended to leverage that (hint: there’s a ‘Big Session Pool’).
But what about a modern, 64-bit version of Windows, say even Windows 10? Well, this technique appears to be mostly dead on such systems — or does it? Is everything truly NX in the kernel, or are there still some sneaky ways to get some executable memory, and to get its address? I’ll be sure to blog about it once Windows 14 is out the door in 2022.

