




![Helping Non-Security Stakeholders Understand ATT&CK in 10 Minutes or Less [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/video-ATTCK2-1)
![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeinc/Edward-Gonam-Qatar-Blog2-1)










































One key building block we use for scaling our machine learning models at CrowdStrike® is Docker containers. Docker containers let us construct application environments with all the dependencies, tools and security our teams need in an easy to maintain pipeline. This ensures that everyone on the team is working on the exact same platform environment during development, data collection, feature extraction and training — all the way to production. However, this can also create challenges because as the number of intermediate containers scale, we need a good way to manage them productively. Don't Repeat Yourself (DRY) is one of the most basic principles for achieving this. As workloads expand to include multiple Docker projects in each team or organization, following this advice can be easier said than done. In theory, Docker projects would be assembled like Legos — picking and choosing the parts needed for each project. By modularizing these dependencies, a team could manage and release updates with semantic versioning and easily keep an entire organization up-to-date. But the reality is far more complex. This lead us to develop what we call Blessed Base Containers (BBCs). These common containers help alleviate some of this complexity by layering Docker images together like a Russian Nesting Doll. As a result, updates, testing and creating new projects are faster, simpler and less costly.
Getting Started with BBC in 3 Basic Step
1. Root Images
It’s important to divide the environment into useful layers, starting at the base with the OS image. This image will act as the root to all subsequent images. We build many of our products off the Ubuntu or Alpine image, but any image can be used as this root. Since this root image will be used by all children, this is a great chance to set up:
2. Intermediate Images
With a root image configured, we next have to consider requirements for applications downstream. By building intermediate images to support specific application types (e.g. web apps, databases, bots, etc.), we can limit the work required in application images. This also introduces a single point in the tool chain where minutiae like special patching or uniform configuration and environment can be implemented. For example, we could build a single Flask image that all individual Flask apps could inherit from, and unify our environment and secret-handling posture. On the data engineering team, we set up specialized images to contain/build our binary tools such as XGBoost or CUDA, providing the next application in the chain with all the required sources built to spec.
3. Application Images
The final layer in our chain is the application image: the Dockerfile in each project’s git repo. Because the common parts have been handled by previous images in the BBC hierarchy, this allows projects to have simpler, understandable Dockerfiles, managing only the application-specific configurations. Applications without this BBC framework tend to look bespoke and complicated, leaning heavily on a few devs to understand the entire environmental picture. By using a layered approach, we cut down on boilerplate code between projects and can more easily roll out major improvements without disrupting every project already released or in development.
Best Practices in BBC
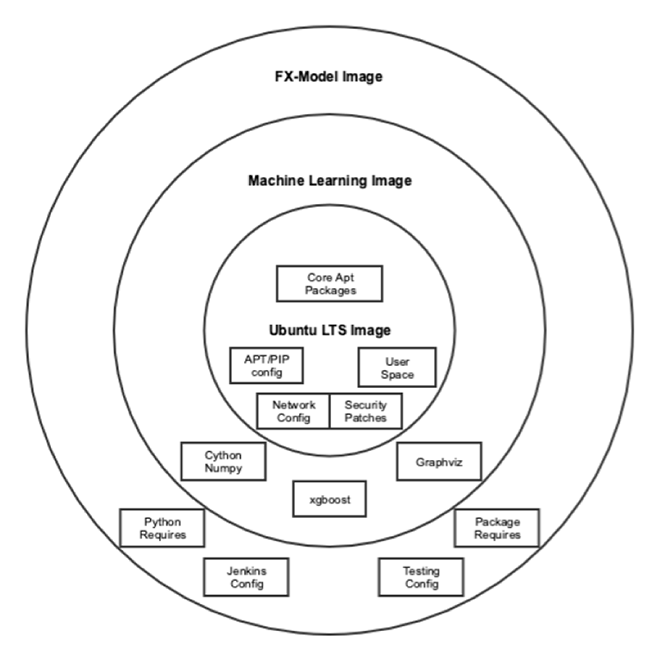 This Diagram Shows the Docker Image Hierarchy
This Diagram Shows the Docker Image HierarchyTesting Images
It's not a good idea to ship applications with test dependencies installed. This leads to larger images and could lead to security and performance issues in production. We simplified our testing concerns in two different ways.
1: Intermediate images:
# Dockerfile.test
ARG SOURCE_IMAGE
FROM SOURCE_IMAGE
RUN setup_tests.sh
# Dockerfile
ARG SOURCE_IMAGE
FROM SOURCE_IMAGE
RUN setup_app.sh ...
# test.sh
docker build \
-t INTERMEDIATE_IMAGE \
--build-arg SOURCE_IMAGE="bbc_image_name" \
-f Dockerfile.test \
.
docker build \
-t TEST_IMAGE \
--build-arg SOURCE_IMAGE="INTERMEDIATE_IMAGE" \
-f Dockerfile \
.
docker run TEST_IMAGE ...
By sandwiching in the intermediate Dockerfile, we are able to install test requirements only in test environments. Also, it is possible to use Docker’s Multi Stage Builds to combine multiple Docker images into one super-image. But in application release, we do not insert the intermediate docker image:
# run.sh
docker build \
-t PROD_IMAGE \
--build-arg SOURCE_IMAGE="bbc_image_name" \
-f Dockerfile \
.
docker run PROD_IMAGE ...
2: Testing via ARGs:
# Dockerfile
FROM bbc_image_name:latest
ARGS PIP_ARGS
COPY . /opt/my_project
WORKDIR /opt/my_project
RUN pip install .${PIP_ARGS}
...
# test.sh
docker build \
-t TEST_IMAGE \
--build-arg SOURCE_IMAGE="bbc_image_name" \
--build-arg PIP_ARGS="" \
-f Dockerfile \
.
docker run TEST_IMAGE ...
Lessons Learned
Having relied on BBCs for over a year as a cornerstone of our product design, here are the best practices our organization has identified in working with BBC:
- Limit updates to the first layer of BBCs and reduce image scope if at all possible. Docker only allows a straight chain of dependencies. This can cause issues in testing or in more complex applications where multiple BBC images might need to be included.
- Use build-triggers from BBC to trigger builds in dependent projects. Users should avoid shipping applications with test dependencies installed. This results in larger images and could lead to security and performance issues in production.
- Schedule time to review and maintain BBCs to bundle updates. It is common practice to pin versions wherever possible, and BBCs are no different. Semantic versioning also allows the team to understand, at a glance, what is released or integrated into any one project. Though the operational complexity has been contained inside a single repository, getting those updates to all the applications can still be difficult.
By following the three steps outlined above and applying our best practices, it is possible to use BBCs as a way to improve speed and performance, making it easier for your organization to update, test and create new projects—all while staying DRY. Are you an expert in designing large-scale distributed systems? The CrowdStrike Engineering Team wants to hear from you. Check out the openings on our career page.
Additional Resources
- Learn how CrowdStrike® extends the protection of Falcon Insight™ to introduce compatibility with Docker, ensuring deep visibility and protection across this emerging critical platform — read the press release.
- Learn more about the CrowdStrike Falcon®®
platform by visiting the product webpage. - Learn more about CrowdStrike endpoint detection and response (EDR) by visiting the Falcon InsightTM webpage.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of Falcon Prevent™ today.


